目錄
1. 描述
Hadoop是個很流行的分布式計算解決方案,Hive是基於hadoop的資料分析工具(data analystic tool)。一般來說我們對Hive的操作都是通過cli來進行,也就是Linux的控制台,但是,這樣做本質上是每個連接都存放一個元資料,各個之間都不相同,這樣的模式用來做一些測試比較合適,並不適合做產品的開發和應用。
因此,就產生Hive的JDBC連接的方式。
2. 步驟
Hive提供了jdbc驅動,使得我們可以連接Hive並進行一些類關係型資料庫的sql語句查詢等操作,首先我們需要將這些驅動拷貝到動態報表與BI商業智慧軟體中的報表工程下面,然後再建立連接,最後通過連接進行資料查詢和資料分析(data analystic)。
2.1 拷貝jar包到Finereport動態報表與BI商業智慧工程
將hadoop里的hadoop-common.jar拷貝至報表工程appname/WEB-INF/lib下;
將hive里的hive-exec.jar、hive-jdbc.jar、hive-metastore.jar、hive-service.jar、libfb303.jar、log4j.jar、slf4j-api.jar、slf4j-log4j12.jar拷貝至報表工程appname/WEB-INF/lib下。
jar包下載地址hbase-finereporter-lib.rar
2.2 配置資料連接
啟動設計器,打開伺服器>定義資料連接,新建JDBC連接。
在Hive 0.11.0版本之前,只有HiveServer服務可用,在程序操作Hive之前,必須在Hive安裝的伺服器上打開HiveServer服務。而HiveServer本身存在很多問題(比如:安全性、並發性等);針對這些問題,Hive0.11.0版本提供了一個全新的服務:HiveServer2,這個很好的解決HiveServer存在的安全性、並發性等問題,所以下面我們分別介紹HiveServer和HiveServer2配置資料連接的方式。
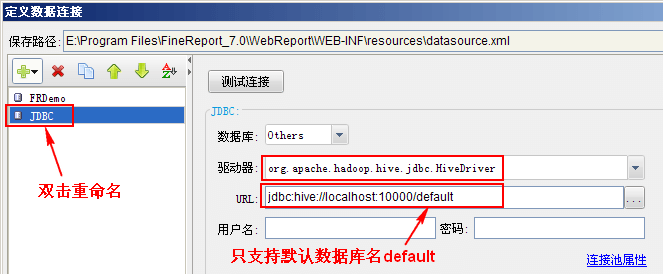
HiveServer
資料庫驅動:org.apache.hadoop.hive.jdbc.HiveDriver
URL:jdbc:hive://localhost:10000/default
註:hive服務默認埠為10000,根據實際情況修改埠;另外目前只支持默認資料庫名default,所有的Hive都支持。
測試連接,提示連接成功即可。
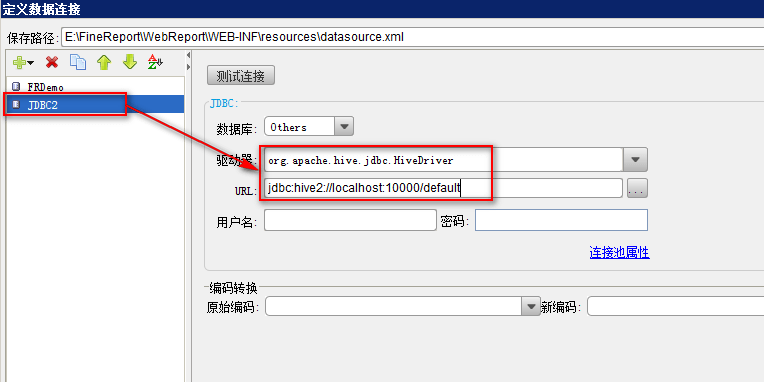
HiveServer2
資料庫驅動:org.apache.hive.jdbc.HiveDriver
URL:jdbc:hive2://localhost:10000/default
註:該連接方式只支持Hive0.11.0及之後版本。
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!