故事引入
本節主要講解通用的資料分析思維方法,説明大家快速建立起體系化的資料分析思維。
“伯樂”相馬

第一個故事是“伯樂”相馬,當然這裡的伯樂並不是歷史上的伯樂,而是來自哈佛大學的一個相馬專家Jeff Seder。傳統的相馬方式認為遺傳是最重要的因素。但是如果我們看看賽馬的獲獎資料,所有獲得年度賽馬最高獎項的後代,有3/4沒有贏得任何主要的賽事。
當然傳統的方式也會看其它的資訊,如馬跑的姿態。但關鍵是沒有任何大家都認為有效的標準。由於又有大量的買主,使得好馬的整個成功的選購概率變得非常低。10年前,一匹有史以來最好的賽馬的後代,被1千6百萬賣出,但只贏了3場比賽,共得到1萬美元的獎金。
而這位Seder,最初也嘗試對馬進行各種的測量,包括鼻孔的大小,心率,肌肉,甚至糞便的重量。但都沒有什麼結果。直到12年前,他有了突破,他決定去測量內臟的大小,他發現左心室的大小和馬的成功非常相關。他通過對馬跑的姿勢的數位化處理,發現一些和成功相關的姿態。他還發現跑一會兒就發出哮聲的馬(相傳我們古代的伯樂典故中,被相中的千里馬就有這個特點),這些馬有的會賣出上百萬。
通常在1000匹賽馬中,只有10匹可以通過Seder的資料標準。而第85號賽馬,它的左心室的大小是99.61%,加上其它的資料,Seder預測它是一匹10萬里挑一,甚至百萬裡挑一的賽馬。18個月之後,在紐約郊區的一個週六的夜晚,這匹馬成為了30年來第一匹得到三連冠的賽馬。
林彪,玩轉大數據的鼻祖

第二個故事是我們的十大元帥之一——林彪,軍隊之中也能用資料分析克敵制勝,運籌帷幄之中,決勝於千里之外。
話說在遼沈戰役開始後,林彪每天深夜都要值班參謀讀出下屬各個縱隊、師、團用電臺報告的當日戰況和繳獲情況。林彪的要求很細,俘虜要分清軍官和士兵,繳獲的槍支,要統計出機槍、長槍、短槍,擊毀和繳獲尚能使用的汽車,也要分出大小和類別。一天,他聽參謀彙報的時候突然說“停”,問“剛才的念的在胡家窩棚那個戰鬥的繳獲,你們聽到了嗎?”,在大家一臉茫然的時候他連問了三句:
“為什麼那裡繳獲的短槍與長槍的比例比其它戰鬥略高?”
“為什麼那裡繳獲和擊毀的小車與大車的比例比其它戰鬥略高?”
“為什麼在那裡俘虜和擊斃的軍官與士兵的比例比其它戰鬥略高?”
他就此判斷,那個戰鬥發生的地方,就是敵人的指揮所。他命令部隊乘勝追擊,並且傳達下口號“矮胖子,白淨臉,金絲眼鏡,湖南腔,不要放走廖耀湘!”。剛剛慶倖脫身的廖耀湘,就這樣成了俘虜。林彪之所以可以做出準確及時的判斷,是和他的資料積累和對資料的敏感分不開的,可以迅速在資料中發現異常點。
作為一個數據人,你需要具備很多的能力,如基本的統計和數學能力,分析能力,建模能力,這些能力可以讓你成為一個不錯的BI工程師。如果更進一步能夠對業務有這更加深刻的理解,根據業務的需求,提出問題,並找到解決的辦法的能力。具備了這個能力,你就有機會成為真正一流的資料科學家。
在這些能力之上,良好的溝通能力,協調能力,能讓你成為一個不錯的資料科學團隊的Leader,可以整合資源,用團隊的力量完成公司重要的項目。
資料分析的戰略思維
提到數據分析師,大家腦海浮現的可能是一些複雜的報表,或者是華麗的數據大屏,亦或是高級的建模手法。但其實分析是我們每個人都具備的能力,例如我們會根據股票的走勢決定是繼續購買還是拋出,根據同一商品不同門店的價格和評價做出最終購買選擇。
前面介紹的這些基於資料的小型決策,其實主要是根據我們腦海中的日常資料經驗來做出判斷的,屬於簡單的分析過程。那麼對於我們數據人或者業務決策者來說,則需要系統的掌握一套科學的、符合商業規律的資料分析方法。
資料分析的目的
對於企業而言,資料分析可以説明企業優化流程,提高營業額,降低成本,而往往我們把這類資料分析定義為商業資料分析。商業資料分析的目標是利用大資料為所有業務決策者做出迅捷、高質、高效的決策,提供可規模化的解決方案。商業資料分析的本質在於能夠創造商業價值 ,驅動企業業務增長。
資料分析的驅動力
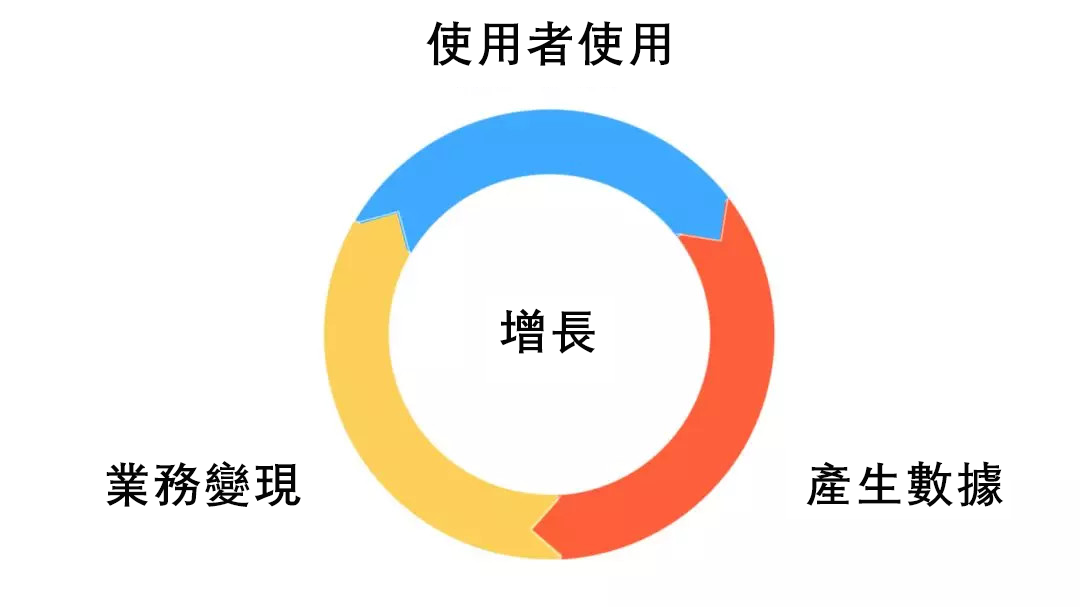
企業在運營的過程中,產生的交互、交易,都可以作為資料獲取下來。透過對這些資料進行分析,不斷優化業務的各個環節,創造更多符合需求的增值產品和服務,重新投入使用者的使用,從而形成形成一個完整的業務閉環。這樣的完整業務邏輯,可以真正意義上驅動業務的增長。
資料分析的進化論
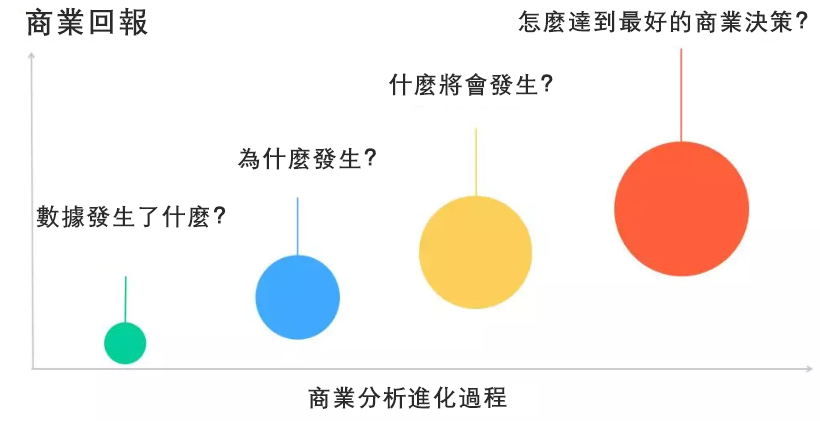
我們以商業資料分析為例,通常會以商業回報比來定位資料分析的不同階段,我們這邊把它劃分為四個階段,分別是觀察當前資料發生了什麼、理解為什麼會發生、預測未來會發生什麼、怎樣達到更好地商業決策。
觀察當前資料發生了什麼?
資料分析的第一步,我們需要觀察當前資料發生了什麼。在企業中,這通常可以使用一些固定報表來做日常的即時資料監控。例如在某一製造企業剛投入一個新設備,那麼則可以通過觀察設備諸如良品率等一系列運行資料來觀察當前設備的運行狀態。再比如互聯網企業新上線了一個產品,我們可以觀察這個產品在投入前期的註冊人數、熱度等一系列資料來知道當前產品的狀態。
理解為什麼會發生?
在觀察當前資料狀態之後,如果發現資料出現異常情況,我們就需要對資料的背後進行深層次挖掘與診斷。例如上面說的製造企業在投入新設備之後,發現設備產出的良品率較低,那麼我們則需要進一步去分析是由於對設備不正當操作導致,還是設備是超負荷運轉,亦或是新設備本身在設計時存在固有缺陷等等原因。這種對資料分多維深度分析,通過FineBI工具的便捷操作能夠極大地提到我們資料的分析和決策效率。
預測未來會發生什麼?
當我們通過對資料的一系列深層分析之後,發現了設備良品率較低的真實原因是設備本身在設計時存在固有缺陷,那麼如果此時還讓它繼續生產,那麼未來良品率自然長期會得不到保障(我們也可以通過資料擬合以及資料採擷的手段,來預測未來的資料)。
怎樣達到更好地商業決策
最後一步,也是所有資料分析工作中最有意義的一步,我們則需要去思考未來應該如何進行業務決策,通過資料分析的結果指導業務決策,精細化運營,以發揮更好的商業價值。
資料分析的基本工作流程
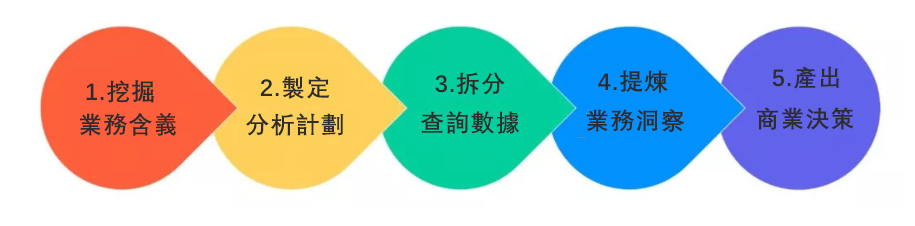
我們前面提到,商業資料分析的本質在於能夠創造商業價值 ,驅動企業業務增長。也就意味著我們的商業資料分析工作需要和最終的業務價值驅動之間有閉環性,一般來說我們可以將資料分析的基本工作流程分為以下七個步驟:洞悉業務背景、制定分析計畫、資料拆分建模、執行分析計畫、提煉業務洞察、產出商業決策、驗證決策效果,形成從資料分析到業務驅動的決策閉環。
洞悉業務背景
第一步,所有商業資料分析都應該以業務場景為起始思考點,脫離實際業務的資料分析是沒有任何商業價值的,意味著它永遠只是一個孤立的數字。我們首先要熟悉業務含義,理解資料分析背後的背景、前提,以及想要關聯的業務結果。
制定分析計畫
第二步,我們需要思考分析思路,並且制定好盡可能全面和完善的分析計畫,例如需要哪些資料表,需要分析哪些維度和指標,對業務場景如何拆分,如何進行資料和業務之間的關聯推斷等。
【歸納推理】 從最終指標(結論)出發,拆解指標
【演繹推理】 從原因出發,推斷結論
MECE原則
一般來說我們會有一個核心需要分析的目標,建議可以按照MECE原則(相互獨立,完全窮盡)對核心指標進行逐步拆解。
內外因素分解法
在按照MECE原則進行核心指標分拆解時,由於有很多因素都可能會影響我們的核心指標。那麼這邊我給大家推薦使用內外因素分解法,把問題拆成四部分,包括內部因素、外部因素、可控和不可控,然後再一步步解決每一個問題。
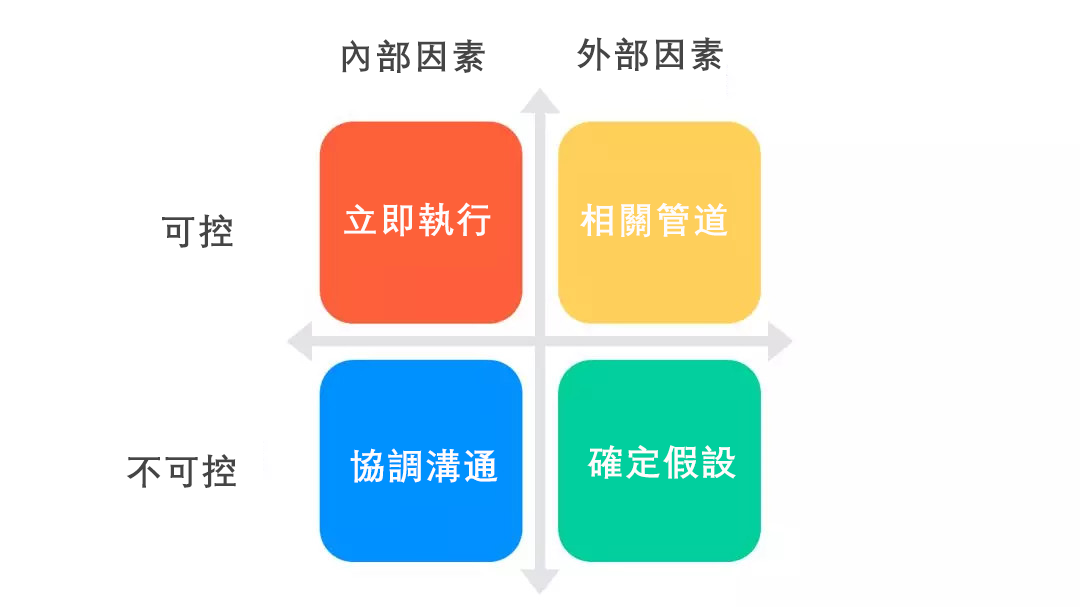
舉個例子:
現在有一個線下銷售的產品。我們發現8月的銷售額度下降,和去年同比下降了20%。我想先觀察時間趨勢下的波動,看是突然暴跌還是逐漸下降。再按照不同地區的資料看一下差異,有沒有地區性的因素影響。我也準備問幾個銷售員,看一下現在的市場環境怎麼樣,聽說有幾家競爭對手也縮水了,是不是這個原因。
按照MECE進行維度和指標的拆解也就是:

例子2:
某自營電商網站,現在想將商品提價,讓你分析下銷售額會有怎樣的變化?
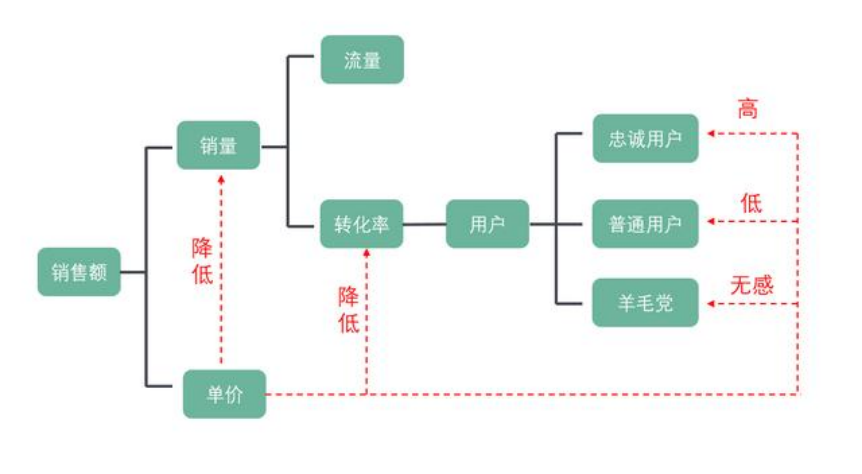
首先可以確定銷量會下降,那麼下降多少?這裡就要假設商品流量情況,提價後轉化率的變化情況,然後根據歷史資料匯總出銷量下降的情況,從而得出銷售額的變化情況。通過MECE核心指標拆解方法的長期訓練,能夠説明我們形成嚴謹的結構化思維邏輯體系。
數據拆分建模
第三步,根據我們制定好的分析計畫,準備和拆分我們真正需要的資料表,進行初步的資料加工和建模,為後續的分析計畫執行做好準備。
執行分析計畫
第四步,開始進行資料視覺化分析,從事先制定好的分析計畫,按照不同的分析角度對資料進行多維分析,對資料背後的業務價值不斷進行精細化的洞察和探索。
提煉業務洞察
第五步,根據分析過程中的猜想和資料驗證,得出提煉之後的業務洞察。
產出商業決策
第六步,根據前面提煉出來的資料背後的業務洞察,指導並進行最終的業務決策。
驗證決策效果
第七步,產出商業決策之後,並不意味著我們的資料分析工作已經真正結束了,我們未來還需要通過一段時間對資料進行觀察和判斷,驗證之前根據資料分析結論指導制定的業務決策,是否真正能夠驅動我們的業務產生價值。
如果發現在進行相關業務決策之後,確實使業務資料發生了改觀,那麼則說明我們前面的資料分析工作確實找到了業務的實際問題所在。否則,則需要返回到第一步繼續進行思考,分析是否是由於之前考慮不周亦或是有偏差。
經典資料分析方法
上面給大家介紹了資料分析的七步基本工作流程,我們在遇到需要進行資料分析的時候,可以幫助我們快速搭建一個清晰的資料分析思路框架。最後再給同學們總結一下我們資料人在日常工作中常用的經典分析方法,讓同學們在遇到不同業務場景下的資料分析問題時能夠更加靈活地去應對。
趨勢分析法
首先是趨勢分析法,也是我們資料人在日常分析工作中使用的最多的方法,它能夠幫助我們快速地説明我們觀察資料的變化趨勢。
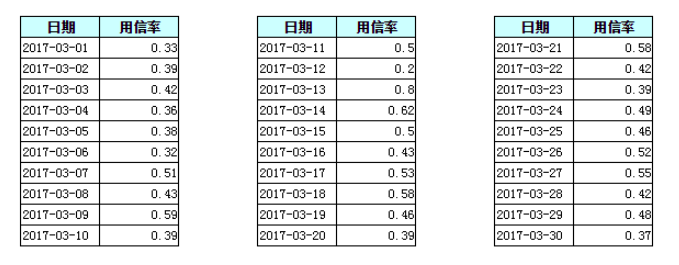
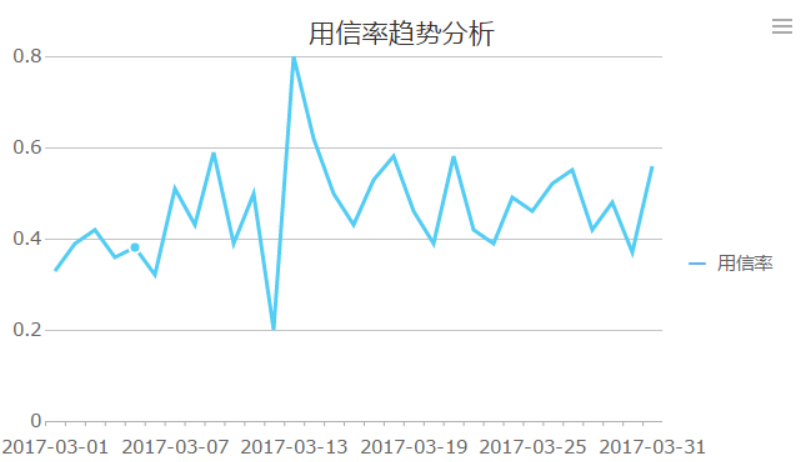
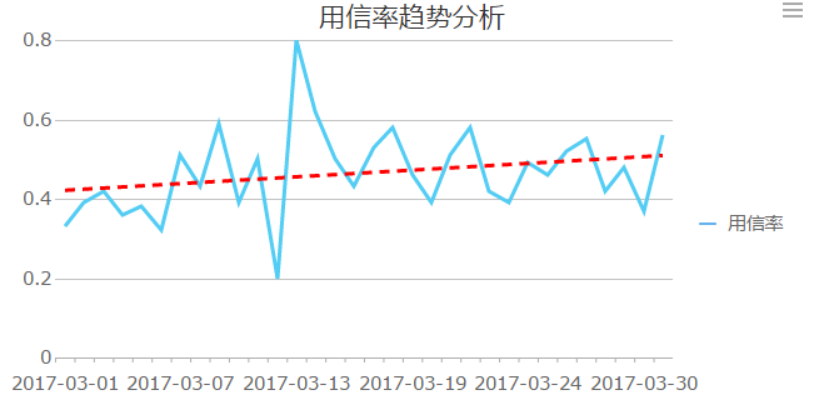
以上圖所示的一個某銀行3月份用信率分析為例,我們分別使用FineReport的表格、折線圖、折線圖+趨勢線擬合的方式進行資料的呈現,我們會發現,通過趨勢分析法能夠快速地説明我們觀察資料變化的趨勢,例如我們可以很快地發現3月13號該銀行的用信率相較于平時發生了突增。
為了更加精准的進行資料的趨勢對比分析,我們還可以引入諸如同比環比等時間細微性的計算方法,來對資料的變化趨勢做更加精准的把控。
多維分析
當我們觀察到的某個數字或者是趨勢是對一個比較宏觀的資料時,我們需要通過對資料進行不同維度的分解,進一步獲得對資料的精細化洞察。
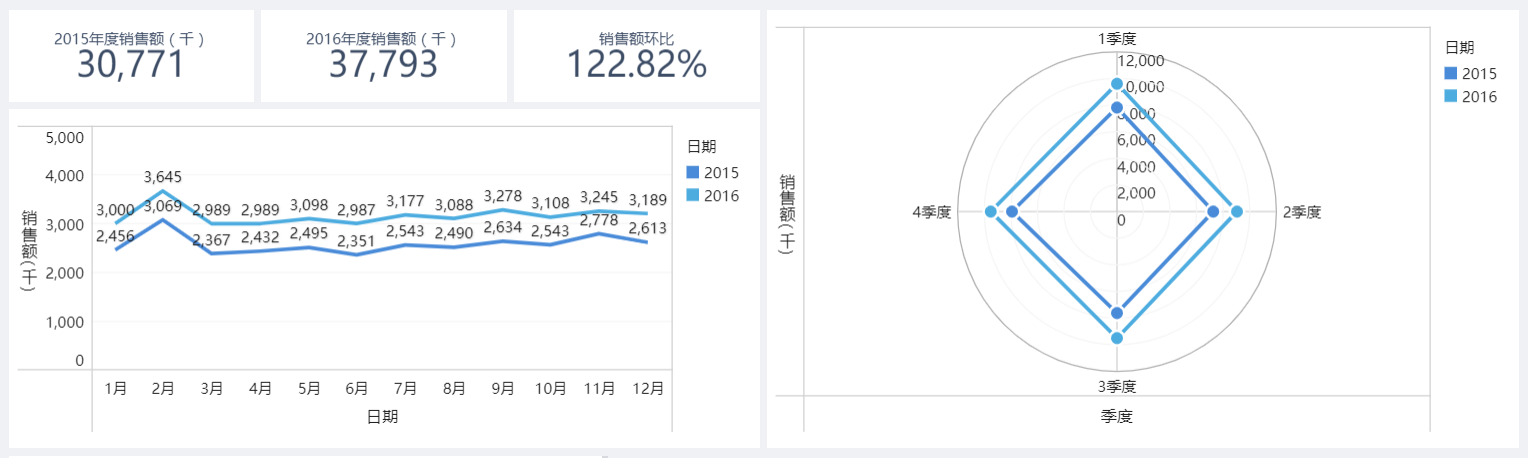
如上圖所示,這是一家牛奶生產企業的某個固定銷售報表的看板,我是這家公司的戰略決策者,那麼我從這樣的固定維度的報表中只能夠得出兩個結論:
1.2016年相比2015年的公司牛奶銷售額相對有所增長,環比增長率位122.82%;
2.每年中各個月份的銷售額相差不大,唯一是在2月份中,可能是由於春節的影響,拉動了大眾的集中消費,所以在每年2月份公司的牛奶銷售額會迎來一個小高峰階段。
如果是傳統的固定報表,那麼資料分析能給使用者傳遞的資訊可能也就到此為止了。可是真的僅僅如此嗎?我們再來引入產品維度分析看看。
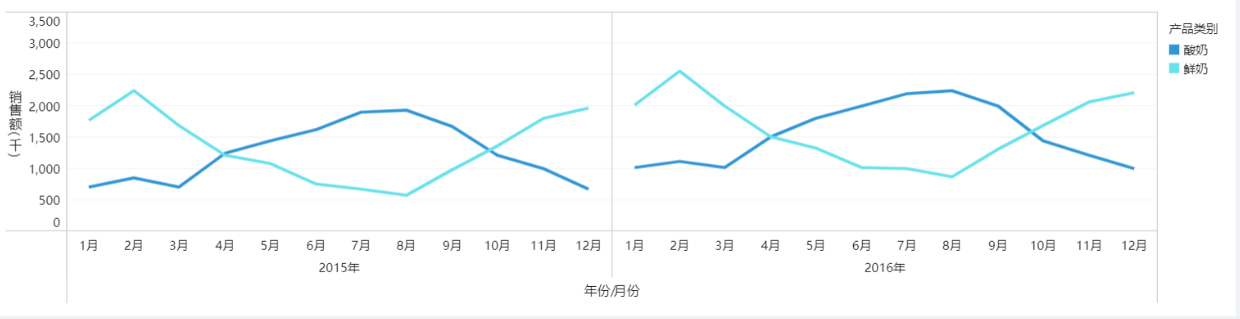
我們可以仔細觀察這個資料分析結果,無論是2015或是2016年,看起來好像每一年中的第一季度和第四季度的鮮奶銷售額比較高,優酪乳的銷售額比較低;而第二季度和第三季度的優酪乳銷售額比較高,鮮奶銷售額比較低。而像固定報表中的單一維度直接匯總,往往就將這樣真正有資料業務價值的結果掩蓋掉了>
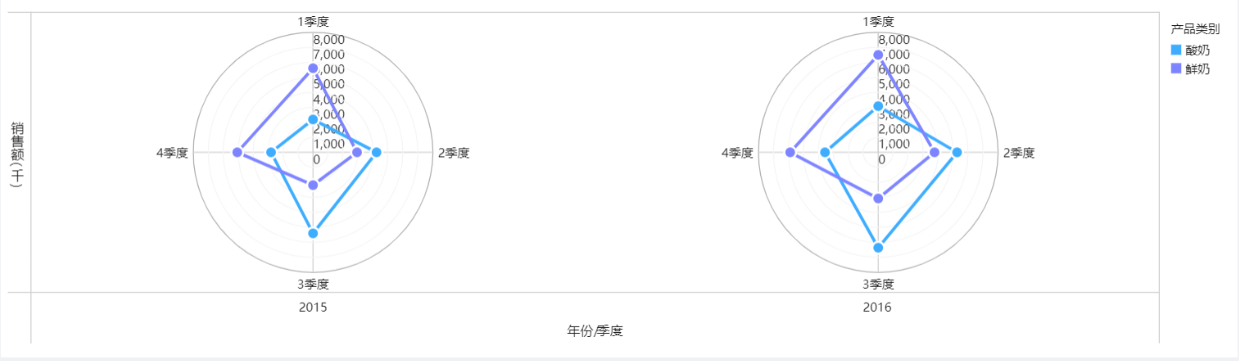
這裡我們進一步來驗證一下。繼續用雷達圖進行每個季度不同產品類別的牛奶銷售額統計,觀察每年季度的銷售額數據統計結果,我們可以輕鬆驗證之前的資料觀察結果。
我們再來從業務的角度進一步思考目前的資料結果原因,第一季度和第四季度主要為春、冬季節,天氣比較冷,這種冷天大家都喜歡熱鮮奶喝,因為比較暖身體。第二季度和第三季度主要為夏、秋季節,天氣比較熱,而這種熱天大家都喜歡和優酪乳,因為比較清爽。
如果我是這家公司的戰略決策者,那麼每年對於第一季度和第四季度,公司將主要生產鮮奶,降低優酪乳的生產量;對於第二季度和第三季度公司將主要生成優酪乳,降低鮮奶的生產量。這樣一來,我們通過逐步的探索分析將資料和業務聯合起來,總體上既能提高企業的產品銷售額,又能降低每個季度公司的庫存壓力。
我們每天遵循的習慣可能會隱藏資料背後潛在的價值,所以我們需要多嘗試從看表格數位思考轉換到看圖形感知分析,勇於改變現狀。在對資料進行探索分析思考時,要善於從不同角度去進行視覺化分析,完善資料全貌,這樣才能發掘資料背後的巨大價值。除此之外,我們還可以借助FineBI的聯動和鑽取功能,一層層抽絲撥繭,直到找到資料最根源的原因。落實到具體的資料工作中,也就是說作為數據人,我們除了分析日常業務提出來的問題之外,還需要學會積極去處理未預見的問題,時刻保持對資料的懷疑態度,練就自己在探索資料業務問題時的前瞻性。
象限法分析
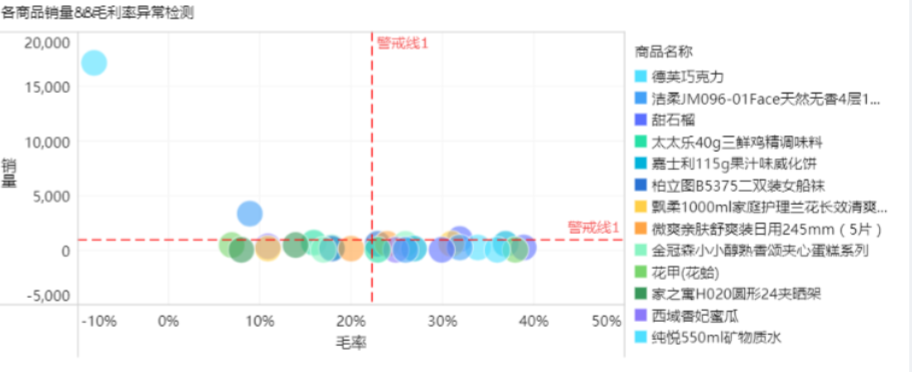
四象限圖是對資料進行分類分析的常見方法,一般是利用水準和垂直分割線將圖表區域分為四個象限,每個象限的資料表現各作為一個類別,圖形形狀主要以點圖呈現。通過象限圖可以幫助我們快速地將多個分類下的資料按照不同指標進行歸類劃分,然後針對不同類別的資料制定最佳策略。
例如我們可以通過四象限圖對不同商品按照銷量和毛利率進行分類分析,快速定位到處於屬於第二象限德芙巧克力的高銷量低毛利異常商品。
轉化漏斗分析
漏斗圖適用於分析具有明確流程節點轉化率的資料分析場景,例如互聯網企業常用的平臺用戶訪問階段漏斗轉化分析、用戶生命週期漏斗轉化分析等。
兩種形式(連續,不連續)的漏斗圖:
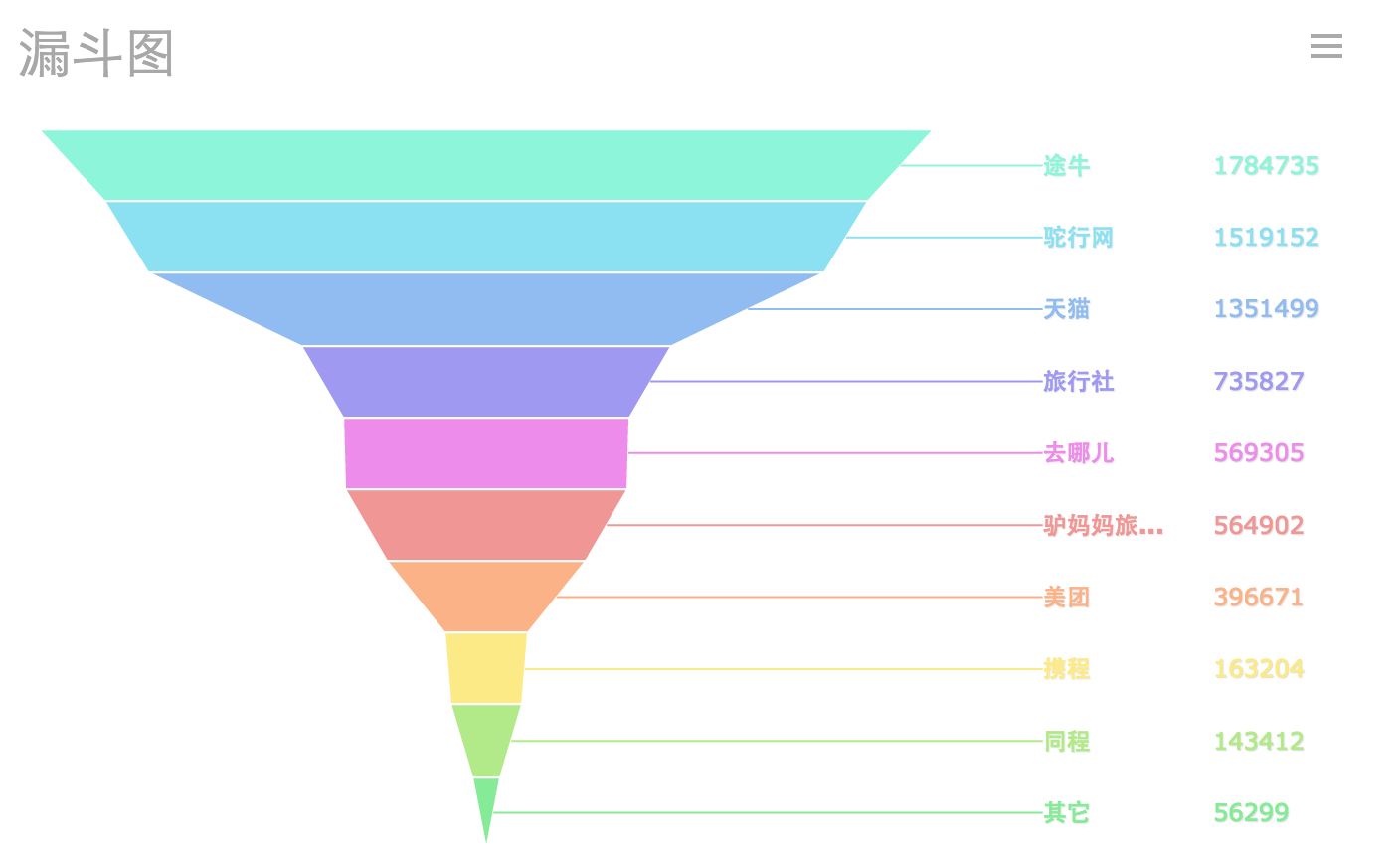

同時,FineReport的漏斗圖支援原樣展示和自動排序兩種資料展示模式。專業資料分析工具的好處就是快捷,工具本身是自帶漏斗模型的,你只需要拖拽操作就能夠完成資料漏斗分析,這一點Excel等軟體是難以實現的,因此軟妹建議還是使用專業軟體。
留存分析
在平臺人口流量紅利逐漸消褪的時代,留住一個老用戶的成本要遠遠低於獲取一個新用戶。每一款產品,每一項服務,都應該核心關注用戶的留存,確保做實每一個客戶。我們可以通過資料分析理解留存情況,也可以通過分析用戶行為或行為組與回訪之間的關聯,找到提升留存的方法。
新增用戶數:新增用戶數=在某個時間段新登錄應用的用戶數
登錄用戶數:登錄用戶數=登錄應用後至當前時間,至少登錄過一次的用戶數
留存率:留存率=新增用戶中登錄用戶數/新增用戶數*100%
次日留存率:
次日留存率=(當天新增的用戶中,在註冊的第2天還登錄的用戶數)/第一天新增總用戶數
第3日留存率:第3日留存率=(第一天新增用戶中,在註冊的第3天還有登錄的用戶數)/第一天新增總用戶數
第7日留存率:第7日留存率=(第一天新增的用戶中,在註冊的第7天還有登錄的用戶數)/第一天新增總用戶數
第30日留存率:第30日留存率=(第一天新增的用戶中,在註冊的第30天還有登錄的用戶數)/第一天新增總用戶數
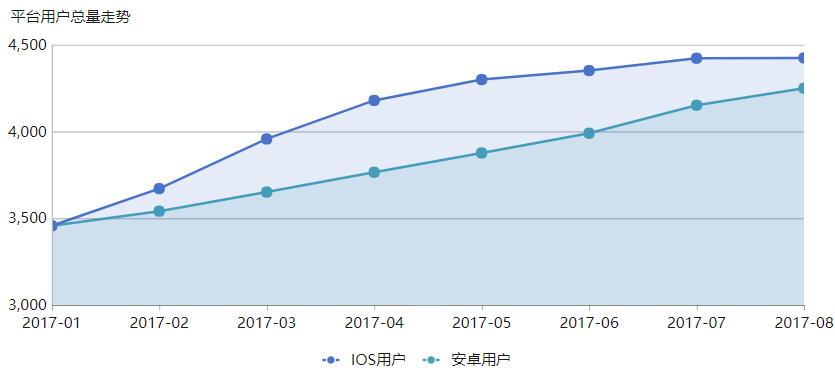
我們先來看到如上圖所示的一組平臺使用者總量走勢資料統計情況,從2017年1月開始,平臺的IOS用戶數量增長較快,到2017年8月份達到了將近4500的IOS總用戶數量。表面上看起來平臺的IOS使用者數量增長情況是要大於安卓用戶增長的,到2017年8月時的總用戶數量也要大於安卓用戶數量。但是我們仔細觀察這兩組資料增長情況會發現,IOS使用者雖然增長快,但是在2017年5月之後總用戶數量趨於平緩,而安卓用戶數量雖然增長慢,但是確是一直保持著穩健增長的趨勢。
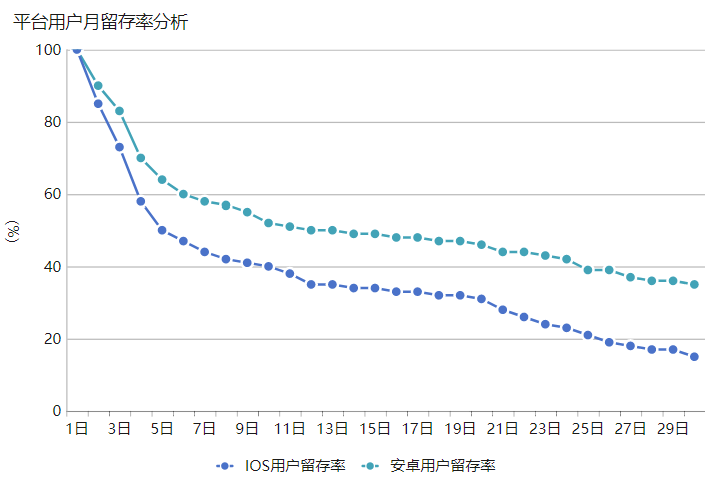
如果你能夠發現這個問題,那麼恭喜你,你已經初具資料分析師的洞察力。這個時候我們就需要關注除使用者增長之外的平臺用戶留存率指標計算統計情況了,下面我們再來繼續看看IOS用戶和安卓用戶的留存率變化對比如何。我們觀察下圖的月度使用者留存率資料統計情況可以看到,一開始IOS和安卓的用戶留存率都是100%,到了第七日IOS的用戶留存率下降至44%,安卓用戶七日留存率是58%,最後到第30日IOS的用戶留存率僅剩15%,而安卓的用戶留存率卻還有35%。這也就不難解釋為什麼平臺高增長下的IOS用戶為何最後留存下來的用戶最後卻不多了,其背後嚴重的用戶流失率是一個不容忽視的問題。
A/B 測試
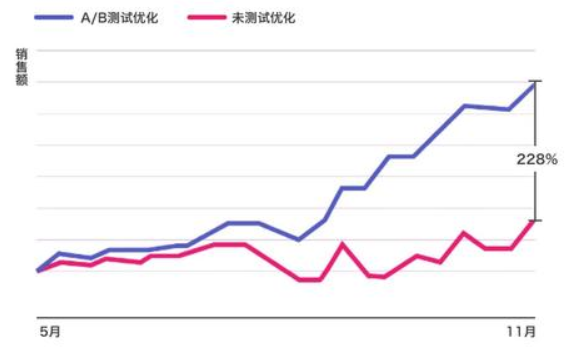
前面講了互聯網企業常用的用戶留存率指標,在產品在上線過程中經常會使用 A/B 測試(增長駭客的一個主要思想之一)來測試不同產品或者功能設計的效果,市場和運營可以通過 A/B 測試來完成不同管道、內容、廣告創意的效果評估,以選擇最佳的轉化方案。
要進行 A/B 測試有兩個必備因素:第一,有足夠的時間進行測試;第二,資料量和資料密度較高。因為當產品流量不夠大的時候,做 A/B 測試得到統計結果是很難的,也會影響結論的準確性。
經典模型(二八、ABC、RFM、購物籃模型等)
這裡著重講下RFM模型和購物籃模型。
關聯分析是一種簡單、實用的分析技術,是指從大量資料集中發現項集之間的關聯性或相關性。若兩個或多個變數的取值之間存在某種規律性,就稱為關聯。關聯可分為簡單關聯、時序關聯、因果關聯。關聯分析的一個典型例子是購物籃分析。該過程通過發現顧客放人其購物籃中的不同商品之間的聯繫,分析顧客的購買習慣。通過瞭解哪些商品頻繁地被顧客同時購買,這種關聯的發現可以幫助零售商制定行銷策略。其他的應用還包括價目表設計、商品促銷、商品的排放和基於購買模式的顧客劃分。
可從資料庫中關聯分析出形如”由於某些事件的發生而引起另外一些事件的發生”之類的規則。如“67%的顧客在購買啤酒的同時也會購買尿布”,因此通過合理的“啤酒和尿布”的貨架擺放或捆綁銷售可提高超市的服務品質和效益。
資料採擷(時序預測、聚類、分類、回歸分析、關聯規則)
回歸分析
回歸分析估計的是兩個或兩個以上變數間的關係。我們可以舉這樣一個例子來幫助理解:
假設A想根據公司當前的經濟狀況估算銷售增長率,而最近一份資料表明,公司的銷售額增長約為財務增長的2.5倍。在此基礎上,A就能基於各項資料資訊預測公司未來的銷售情況。
使用回歸分析有許多優點,其中最突出的主要是以下兩個:
- 它能顯示因變數和引數之間的顯著關係;
它能表現多個獨立變數對因變數的不同影響程度
除此之外,回歸分析還能揭示同一個變數帶來的不同影響,如價格變動幅度和促銷活動多少。它為市場研究人員/資料分析師/資料科學家構建預測模型提供了評估所用的各種重要變數。具體可參考這篇文章《這7種回歸分析方法,資料分析師必須掌握!》
以上部分圖表來自FineReport製作,歡迎大家免費試用!
免費下載FineReport10.0

學會數據分析思維,是不是覺得意猶未盡,沒關係,帆軟12/6在台北準備了一場超200人的盛會,我們會在會議中討論行業前沿話題,實例方案和一些資料分析工具等等,如果你是數據大咖,或是想成為數據行業的佼佼者,千萬別錯過這樣一場有內容有趣有意義的活動!
前往報名
相關文章:
細數那些最有意思的資料視覺化!
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!