目錄
最近經常有做報表的朋友向我抱怨,做報表開發太難了,難得不是自己不會做報表,而是公司的報表系統實在是太差了,隔三差五就會因為資料量過大而造成宕機,一宕機報表平臺就停轉,報表系統一停轉資料就會丟失,造成的嚴重損失不說,最難受地是每天都要擔驚受怕。
這讓我想起了之前我們曾經用過的一家國內廠商的報表平臺,在業務不多的時候表現還很正常的,沒有出現什麼問題,但一旦到了業務高峰期就絕對要出問題。
有一次,我們發現報表系統不能切換視窗了,我就想趕緊把資源切換到另一個伺服器上,卻發現無論怎麼操作都沒辦法把資源切換過去,領導們聽說這個事都趕過來了,圍在周圍商討如何解決,同時急電技術支持。
後來我終於發現問題:
報表系統在資料庫的日誌讀取時因為資料量過大,直接造成了系統的卡死,以致業務系統宕機,無法處理業務請求。
等到我們處理好故障之後,看看時間,這時間已經過去一個小時了,相關外聯單位的打來的電話已經打爆了,耽誤了業務系統的處理,大家都走不了。
這也說明,當我們在為企業選型報表工具的時候,不單單要關注報表工具的靈活性、功能性和性價比,更重要地要關注它的功能性和技術性,這些都是普通業務人員無法發現的。
按照我們這幾年的經驗來說,國外諸如JasterReport、BIRT這樣的基本不用考慮了,國內廠商的話,技術比較成熟的也就是FineReport等一些工具吧,基本上報表平臺的穩定性都很強,基本沒有出現過宕機情況。
下面我就結合報表平臺FineReport,以及自己的經驗,總結了下面五個硬技術,來簡單梳理一下一個優秀的報表工具應該具有什麼樣的“高精尖”技術:
一、Web業集
什麼叫做業集呢?簡單類別一下,有一家銀行只開放了一個業務辦理視窗,但是來辦理業務的人有100人,因此大家排起了長隊,突然這個視窗的銀行櫃員忙暈了過去,於是視窗上便掛出了“暫停服務”的牌子,整個隊伍就要等待視窗重新開放。
如果你是行長,你會怎麼辦?你肯定會說,這還不簡單,多開放幾個視窗一同辦理不就行了。
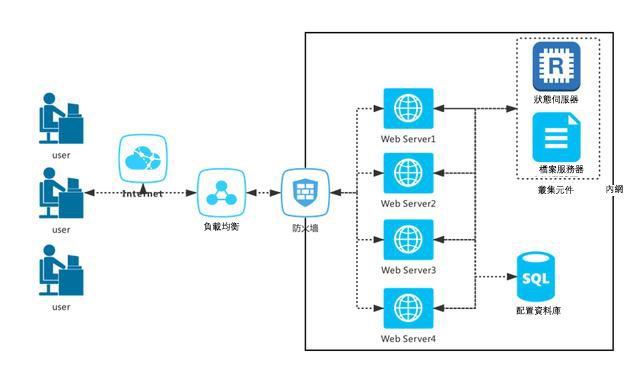
對了!這就是業集,報表伺服器就相當於銀行的視窗,以前我們都是把所有的工程負載都集中到一台主機上,也就是只有一個視窗,但是資料一旦達到閾值,就會產生宕機(也就是“暫停服務”),這個時候整個系統就會失效停斷,這個時候我們就需要業集,來增加伺服器節點實現併發線性增長:
這也是解決宕機的一種常用方法,依據演算法將需求合理分配到各個節點上,任何一個節點宕機都不會影響系統的正常工作,也就是“無主機模式”。
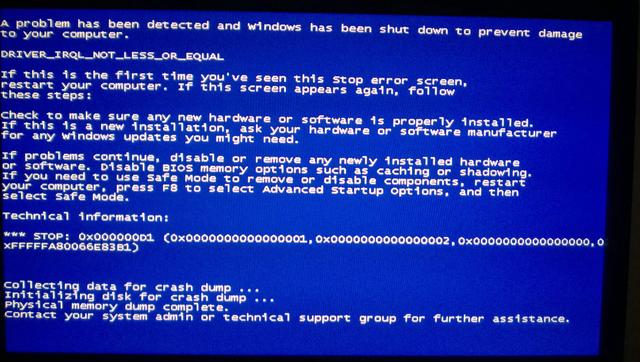
後來我發現FineReport擁有著一套非常成熟的業集架構,我將其總結為[負載均衡+web容器+狀態伺服器+檔案伺服器+外置資料庫],這幾乎可以成為國內報表業集方案的標準範本!
負載均衡就是合理分流,速度快的節點多分一些,速度慢的少分一些,這也是業集系統的入口。
web容器相當於銀行櫃檯,作用是處理用戶端發出的請求。
有了請求就要進行驗證和緩存,狀態伺服器就是用來管理伺服器緩存的。
檔案伺服器相當於銀行前臺的電腦,保證每個視窗的資訊同步更新,也就是資源檔的即時一致性。
最後,雖然伺服器節點有很多,但還要用同一個外置資料庫才行,這樣才能保證節點之前的配製資訊是一樣的。
二、強大引擎
做報表開發的都知道,我們所有的報表日誌和檔都需要寫入資料庫,需要資料的時候再從資料庫裡提取,但是很多報表工具在日誌存取上的效率很差,一旦日誌過大就會導致系統過慢甚至宕機。
這裡我想說一下FineReport自主研發的Swift引擎,其實就是一個分散式資料庫,我們可以理解為是一個公共帳本,你可以在這個帳本上寫資料,我也可以寫資料,我可以看被人記錄的資料,也能拿到自己單獨的資料。
但是這個公共帳本能允許記錄多少資料?會不會在查詢的時候要排隊?會不會因為資料太多導致崩潰?我想要看資料的時候會不會影響別人?
而這也正是Swift引擎真正強大的地方,以上的問題我也曾經擔心過,但是很驚訝swift引擎全都解決了:
首先,swift採用的不是cube導入資料才能查詢的方式,而是換了一套資料結構,資料只要插入了就可以零延遲查詢,根本不需要排隊;
而且理論上支援資料的無限增長,只要不超過單機的物理瓶頸,你就可以放心地往這裡放資料;
最後,swift引擎支援非對稱分散式,服務之間職責分工明確,互不干擾,比如導入機器跟查詢機器分開,避免導入資料時太占資源影響查詢。
三、基於 JVMTI 的增強記憶體管理技術
這個技術雖然聽起來比較深奧,但是我發現這是提高報表平臺穩定性的最好辦法!
很多其他工具是怎麼預防宕機的呢?方法比較簡單,就是一旦負荷超載了,記憶體達到了一定閾值就要排隊,永遠預留一定的記憶體空間,防止其宕機時記憶體空間不足,但同時也會產生一個問題——不宕機的時候也要持續排隊。
而不得不佩服FineReport系統,他們應該是深入研究了JVM GC機制的底層原理,採用了JVMTI去檢測jvm的程式設計介面,加入了強制GC機制:
也就是記憶體達到閾值後進入排隊,觸發一次GC,如果沒有釋放足夠空間,就再次GC;而如果記憶體達到閾值後觸發了GC,釋放的空間足夠用,系統就會繼續運行,不會繼續觸發GC,這樣就不會導致宕機了,可以大大增加平臺的穩定性。
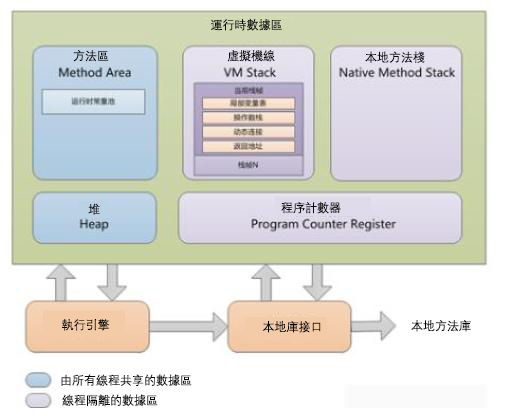
四、HTML解析技術
大家都知道HTML是用來書寫網站的一種語言,在我用之前的報表工具列印匯出報表範本時,經常會遇到【以html顯示內容】的情況,就可能會造成匯出後資料有誤、線條不顯示等等,後來我找到了真正原因:
因為如今使用者開發的系統基本上趨向於BS架構的流覽器,這些系統可能由不同的語言開發,包括HTML、ASP、JSP、PHP等,如果我們要將製作好的報表嵌入到這些頁面中,就要進行HTML的解析,而你的工具要是沒有這個技術,就會出現上面的情況。
而像我這樣的碼農一般就會直接找原始程式碼,調用參數才能解決,但是對於很多業務人員來說基本上就是無能為力了。
五、大數據集匯出
在進行報表開發的時候,經常遇到一個問題:當我匯出大資料量的範本時,極容易存在時間過長或者記憶體佔用過大的情況。
這是為什麼呢?因為你在對資料集進行取數的過程中,必須現在進行報表計算,然後才能匯出,類似於excel的函數計算,會大大增加宕機的風險
後來我詢問了FineReport的開發人員才明白了FR是如何在技術層面解決大數據集導出問題的:
首先,他們使用的是SXSSFWorkbook流式行匯出,速度真的非常快,而且他們採用的是生產者消費者模式,一個執行緒用於取數,把資料行存在佇列中,另一執行緒讀取行匯出。
通俗點說,生產者就是生產資料的執行緒,消費者就是消費資料的執行緒,如果生產者處理速度很快,而消費者速度很慢,那麼生產者就必須等待消費者處理完,才能繼續生產資料,反之亦然。
而FineReport系統的生產者消費者模式就相當於充當了一個容器,生產者和消費者彼此之間不直接通訊,生產者生產完資料之後不用等待消費者處理,直接扔給阻塞佇列,消費者也不找生產者要資料,而是直接從阻塞佇列裡取,阻塞佇列就相當於一個緩衝區,平衡了生產者和消費者的處理能力。
總結
對於一個從事了十年報表工作的人來說,一個成熟的、強大的、簡潔的報表平臺工具是極為重要的,它不光要解決各種中國式的複雜報表,最主要的是它要能夠為企業快速搭建起資料平臺,這樣的工具才是真正對企業來說有用的,否則都只是空有其表,華而不實!
獲得帆軟最新動態:數據分析,報表實例,專業的人都在這裡!加入FineReport臉書粉絲團!
相關文章:
再見Python +Excel VBA!我終於等到了一鍵生成報表範本的神器
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!