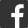了解過數據倉庫歷史的人都知道Bill Inmon、 Ralph Kimball。 Bill Inmon 代表作《Building the Data WareHouse》 , Ralph Kimball代表作為 《The Data Warehouse Toolkit》、《The data Warehouse lifecycle》。兩位大師對數據模型都分別作了深入闡述,個人理解的數據模型是數據平台的靈魂。數據模型設計好了對數據應用、數據分析支援是非常有幫助的。尤其 kimball 提出的維度模型 ,圍繞業務模型能夠直觀的表達業務數據關係。
關於數據模型概念不多講,本文與大家分享多維數據模型設計的十個技巧。
技巧一:維度表中應該包含最細的顆粒度
通常在數據平台做開發的同學,「特麽」經常抱怨 「 需求怎麼又變了,這個需求能不能不要來回的改「,數據建設中會遇到非常不確定性需求,不可預測篩選與匯總。
尤其是在互聯網做數據化運營,絕大部分需求幾個匯總類指標是無法滿足需求,很多時候會沉浸到比較明細、更深層次的細節信息。當然匯總指標是能夠概括一些概述數據細節,但只有細節數據才能回答各種不停的業務上數據追問。
技巧二: 圍繞業務流程來構建維度
數據是真實的反應業務活動與成果的,業務流程在不同的階段所產生數據項也是不一樣的。比如說一個用戶從尋找App、下載、安裝、啟動、再啟動這個流程,用戶在淘寶購物、尋找瀏覽物品、放入購物車、跳轉收銀台、支付、完成。
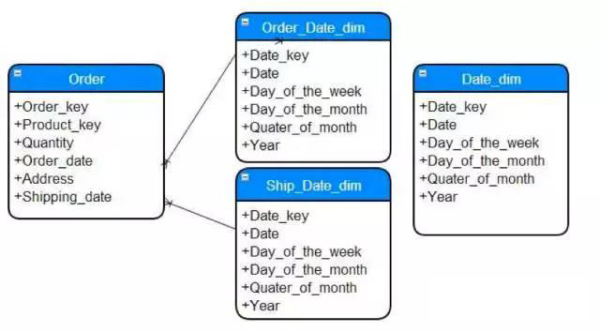
這兩個流程背後代表某個業務事件活動,在不同的環節產生的數據項是不同的,如果將流程不同階段的指標沉澱下來變為可度量的關鍵指標,如果將這些關鍵指標根據關係合并與設計到事實表中,就變為支撐業務人員分析、探索業務的細節數據。
為了能夠從業務流程上的多維度來探索數據,所涉及到的很多維度最好是業務流程來做設計,比如上圖交易現相關,從訂單的來源,所屬產品、到支付階段的資金來源,從業務流程上來看,還可以擴展出更多的維度、與度量值。
在不同的業務環節,業務人員都會「很任性」的需求不同指標,但是在需求中往往是與業務流程有很大關係的。
技巧三:盡量保證每張事實表與時間維度有關聯
在原則二中描述那兩個案例業務永遠是與日期有關係的,不管是月、日、年、還是分、秒,財務年、自定義時間事件段等。
每個事實表至少有一個外鍵能夠與日期維度表相連,時間維度能才能反映出存量與流量,才能分析某一時刻、某一時間段的業務流程變化情況。
技巧四:同一張事實表的指標對應維度層級必須一致
一般的事實表有四種類型,粒度事實、周期性快照事實、聚合快照事實、非事實事實表,不管它們的粒度類型,事實表中的每個度量值在顆粒度上必須保持與維度的顆粒度是一致的,否則就等著崩潰吧。
例如原則二給出的案例,要分析一個用戶訂單支付業務。如果對這個業務進行設計分析模型時,把產品維度粒度定義為產品,但是在度量值金額卻是按照不同產品分類做聚合的,那就有意思了。我暫時也沒回憶起類似的場景會在什麼情況犯錯。
技巧五:處理好事實表和維度表之間的多對多關係
在多個維度表的值可以賦給單個事實事務時,事實表和維度表之間通常是多對多關係,比如為了計算寫書的作者分成,一本書可能有多個作者, 一個作者可能出版了多本書,這個案例下就是多對多的關係。要考慮到可以計算出每個作者的的分成,中間可以增加一個橋接表。
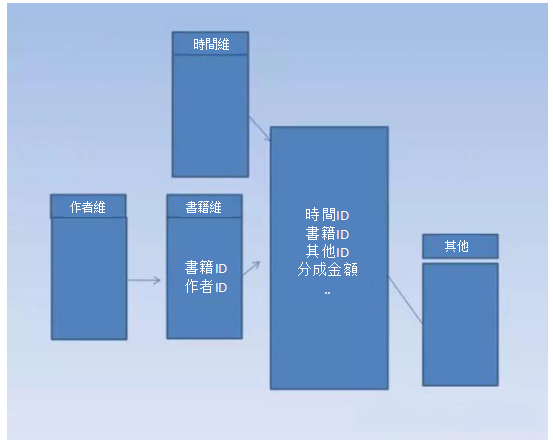
綜上所述,在這種情況下多個值的維度與事實表直連可以採用橋接表來處理。
技巧六:經常發生變化的維度處理
在設計維度上很多時候都是扁平化處理,業務中普遍的維度關係是一對一的關係,比如例如客戶Simmy將自己的地址由原先的Addr1改為Addr2。這時我們需要將這個記錄了客戶Simmy的記錄中的有效截止日期改為現在,並重新添加一條有效截止日期為現在的和一個新的版本號且Address為Addr2的記錄。
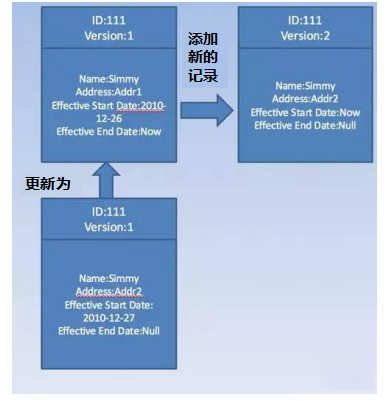
但是也經常存在一對多的關係,比如大家的購物郵寄地址、個人電話號碼等在現實生活中有變化的處理。這種情況可能存在一對多的關係,假如一張維表存在上百萬的維度且匯總信息經常在變化,那得注意做緩慢變化、或快速變化處理了。
技巧七:讓維度表使用代理鍵
英文叫SurrogateKey,翻譯過來又叫代理鍵,在建模中通過一些毫無意義鍵值來代替一些業務鍵值,有利於維度統一整合。
技巧八:進行一致性維度的處理
一致性維度,又叫統一維度。對於構建企業級數據平台數據模型具有關鍵的意義,通過在數據轉換處理環節一次性處理後,在構建不同數據集市、不同數據層時可以反覆被使用。
統一維度在構建多維模型時,可以很便捷能把多種不同類型業務指標進行關聯,讓使用用戶在不同業務間切換分析、還能減少維護工作。
比如數據描述經常不一致性如,同名異義、同物異名,還有口徑多樣化、編碼不統一、命名不統一等。還能處理一些未知、不知道名字、日期待定等一些含糊的分類。
而然,在實施統一維度時最大的障礙是需要不同的業務部門、IT部門對每個維度屬性上達成一致,那就涉及到數據管理、數據治理的範疇了。比如含義相同但名稱不同業務術語等。
技巧九:分析功能標籤化標籤以及過濾器等信息可以當做維度來保存
其實這也不是什麼原則,個人更傾向于歸類到技巧中。比如在構建分析型數據產品時,有些功能性的標籤、查詢類的代碼或分類完全可以維度化。
例如某些下拉菜單中篩選標籤以及過濾器閾值等、用戶的特定群體探索、產品的相關聯分析等,都可以維度化並做預處理。
這樣做的好處是速度快,把部分分析結果數據做預處理,查詢中需要聚合部分變為過濾查詢,這樣會提高分析查詢效率的。
技巧十:大維度的退化處理
所謂的大維度,是指維度數據量特別大,比如現在互聯網的URL維度可能幾十萬上百萬,還有客戶,產品等等。一個大的企業客戶維度往往有上百萬記錄,每條記錄又有上百個欄位。而大的個人客戶維度則會超過千萬條記錄,這些個人客戶維度有時也會有十多個欄位,但大多數時候比較少見的維度也只有不多的幾個屬性。
這些維度的處理往往採用把大屬性轉為小屬性、退化處理,增加更多的不同分類欄位等特殊處理。
作者:松子(李博源)
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!