無論是採集數據,還是存儲數據,都不是大數據平台的最終目標。失去數據處理環節,即使珍貴如金礦一般的數據也不過是一堆廢鐵而已。數據處理是大數據分析軟體產業的核心路徑,然後再加上最後一公里的數據可視化,整個鏈條就算徹底走通了。
數據處理的分類
如下圖所示,我們可以從業務、技術與編程模型三個不同的視角對數據處理進行歸類:
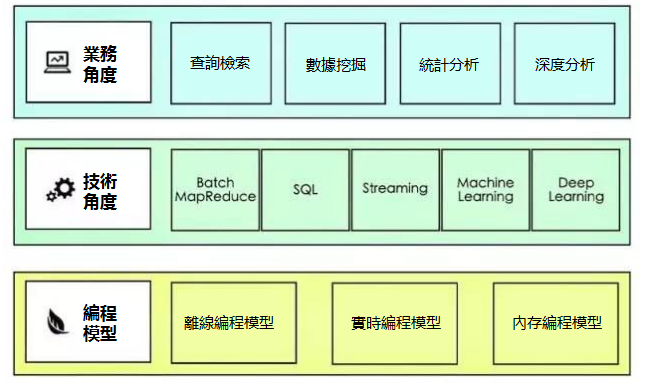
業務角度的分類與具體的業務場景有關,但最終會制約技術的選型,尤其是數據存儲的選型。例如,針對查詢檢索中的全文本搜索,ElasticSearch會是最佳的選擇,而針對統計分析,則因為統計分析涉及到的運算,可能都是針對一列數據,例如針對銷量進行求和運算,就是針對銷量這一整列的數據,此時,選擇列式存儲結構可能更加適宜。
在技術角度的分類中,嚴格地講,SQL方式並不能分為單獨的一類,它其實可以看做是對API的封裝,通過SQL這種DSL來包裝具體的處理技術,從而降低數據處理腳本的遷移成本。畢竟,多數企業內部的數據處理系統,在進入大數據時代之前,大多以SQL形式來訪問存儲的數據。大體上,SQL是針對MapReduce的包裝,例如Hive、Impala或者Spark SQL。
Streaming流處理可以實時地接收由上游源源不斷傳來的數據,然後以某個細小的時間窗口為單位對這個過程中的數據進行處理。消費的上游數據可以是通過網路傳遞過來的位元組流、從HDFS讀取的數據流,又或者是消息隊列傳來的消息流。通常,它對應的就是編程模型中的實時編程模型。
機器學習與深度學習都屬於深度分析的範疇。隨著Google的AlphaGo以及TensorFlow框架的開源,深度學習變成了一門顯學。我了解不多,這裡就不露怯了。
機器學習與常見的數據分析稍有不同,通常需要多個階段經歷多次迭代才能得到滿意的結果。下圖是深度分析的架構圖:
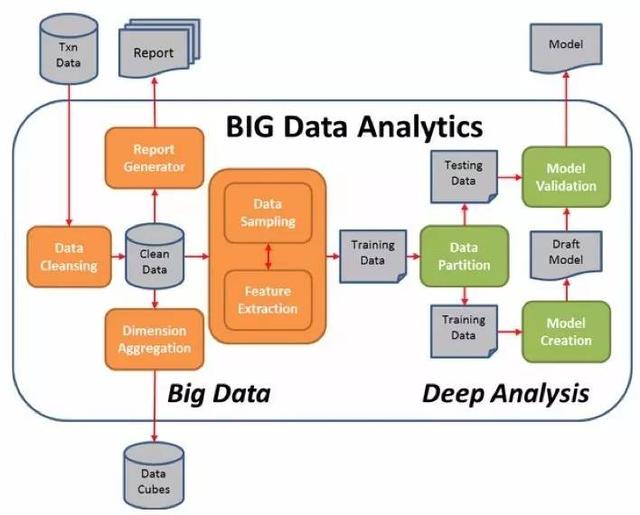
針對存儲的數據,需要採集數據樣本並進行特徵提取,然後對樣本數據進行訓練,並得到數據模型。倘若該模型經過測試是滿足需求的,則可以運用到數據分析場景中,否則需要調整演算法與模型,再進行下一次的迭代。
編程模型中的離線編程模型以Hadoop的MapReduce為代表,內存編程模型則以Spark為代表,實時編程模型則主要指的是流處理,當然也可能採用Lambda架構,在Batch Layer(即離線編程模型)與Speed Layer(實時編程模型)之間建立Serving Layer,利用空閑時間與空閑資源,又或者在寫入數據的同時,對離線編程模型要處理的大數據進行預先計算(聚合),從而形成一種融合的視圖存儲在資料庫中(如HBase),以便於快速查詢或計算。
場景驅動數據處理
不同的業務場景(業務場景可能出現混合)需要的數據處理技術不盡相同,因而在一個大數據系統下可能需要多種技術(編程模型)的混合。
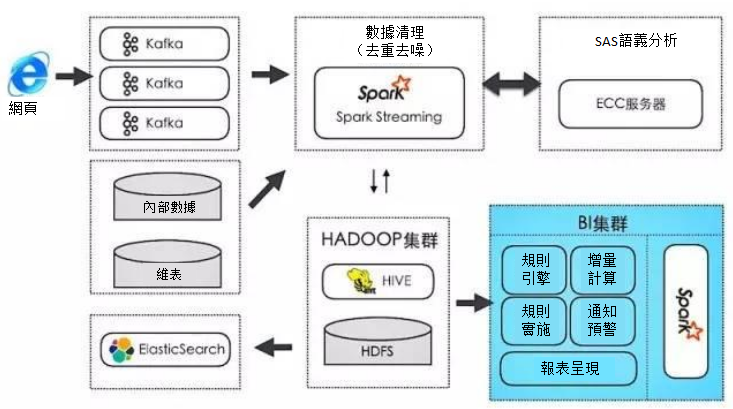
場景1:某廠商的輿情分析
某廠商在實施輿情分析時,根據基於需求,與數據處理有關的部分就包括:語義分析、全文本搜索與統計分析。通過網路爬蟲抓取過來的數據會寫入到Kafka,而消費端則通過Spark Streaming對數據進行去重去噪,之後交給SAS的ECC伺服器進行文本的語義分析。分析後的數據會同時寫入到HDFS(Parquet格式的文本)和ElasticSearch。同時,為了避免因為去重去噪演算法的誤差而導致部分有用數據被「誤殺」,在MongoDB中還保存了一份全量數據。如下圖所示:
場景2:Airbnb的大數據平台
Airbnb的大數據平台也根據業務場景提供了多種處理方式,整個平台的架構如下圖所示:
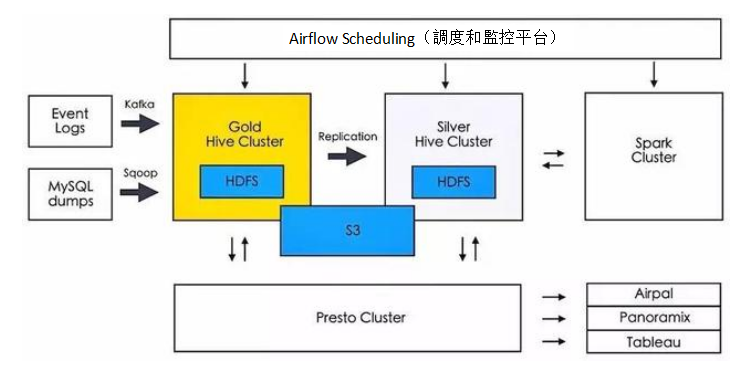
Panoramix(現更名為Caravel)為Airbnb提供數據探查功能,並對結果進行可視化,Airpal則是基於Web的查詢執行工具,它們的底層都是通過Presto對HDFS執行數據查詢。Spark集群則為Airbnb的工程師與數據科學家提供機器學習與流處理的平台。
大數據平台的整體結構
行文至此,整個大數據平台系列的講解就快結束了。最後,我結合數據源、數據採集、數據存儲與數據處理這四個環節給出了一個整體結構圖,如下圖所示:
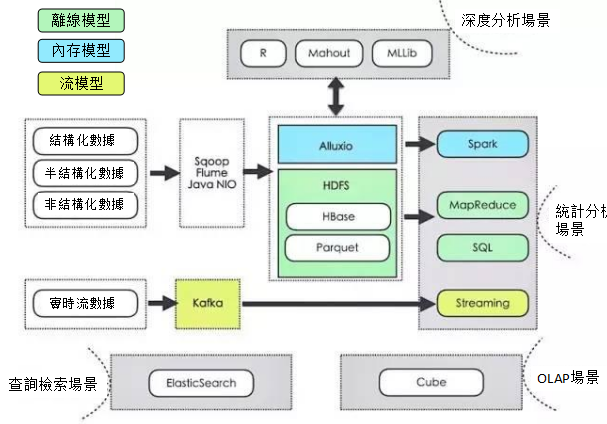
這幅圖以查詢檢索場景、OLAP場景、統計分析場景與深度分析場景作為核心的四個場景,並以不同顏色標識不同的編程模型。從左到右,經曆數據源、數據採集、數據存儲和數據處理四個相對完整的階段,可供大數據平台的整體參考。
標籤 | 大數據 架構
作者 | 張逸
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!