面對紛繁複雜的大數據生態,人們常常用亂花漸欲迷人眼的字樣來描述。因所處背景和位置差異,每個人對大數據的反應也各有不同,或疑惑、或欣喜、或鄙視、或無奈。大數據很通俗,每個人都可以聊聊。大數據也很神秘,很多觀點其實並不清楚在表達什麼。
本文嘗試從生態視角聊一下大數據的現狀,並以反欺詐模型為例簡述一下大數據挖掘的未來發展。希望聊大數據的時候能處於同一平面,浮於表面的觀點或雞同鴨講的交流都屬於浪費時間。
金融科技「四大俗」
大數據的火爆,以及大數據給人造成的反感,一個很大原因在於其內在偏虛。我們不能光說價值,總得拿出點看得見摸得著的東西。大數據不是獨立存在,還要關注幾個相關的領域。從邏輯上看,大數據的下面可以是雲計算和區塊鏈,上面是人工智慧,這就是之前在朋友圈隨口說的的金融科技「四大俗」。俗的一個原因是由媒體爆炒引發了連鎖反應,鄙視不負責任的忽悠和開的比瓢都大的腦洞。為人處事需要好好學學基本道理,「兩學一做」其實不錯。
四個熱門領域都是我關注的,實際上這四個處於不同的發展階段。目前雲計算已經比較實在了,企業可能已經關注盈利了。大數據整體還在穩步發展,關注的是多行業、多領域的應用。人工智慧離科幻電影裡面的AI還很遙遠,目前火爆的是特定領域的應用。至於區塊鏈,還是以概念、模式為主,killer application還沒有,理論和實踐都需要持續完善。
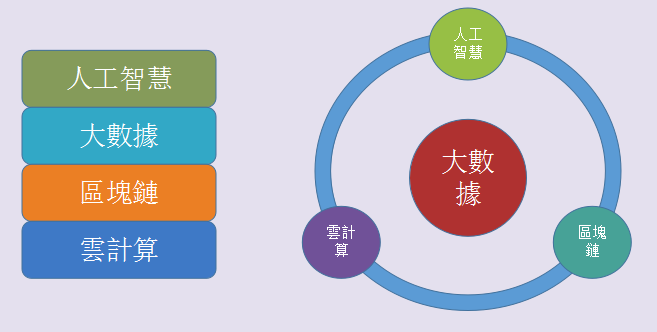
關於四者的結構關係,畫了兩個圖。左邊的是層次分割,從基礎到應用。右邊的是以大數據為核心,硬的環繞軟的,將大數據作為原油或血液的比喻了;其實還可以加上物聯網,不過在金融科技裡面談的還不是太多。
當我們開始討論大數據的時候
相比雲計算的踏實,人工智慧和區塊鏈的高冷,只有大數據是真的「俗」。似乎所有的人都可以聊聊,有人專心聊思維,有人聊商業模式,有人做數據治理,有的人聊數據資產。當然,更多的人集中在技術和應用上面。總體而言,大數據應用是核心驅動力,基於新思維、新技術開採數據資源,並構建相應的商業模式;過程中數據治理貫穿始終,確保各層協同一致,保障數據價值創造。
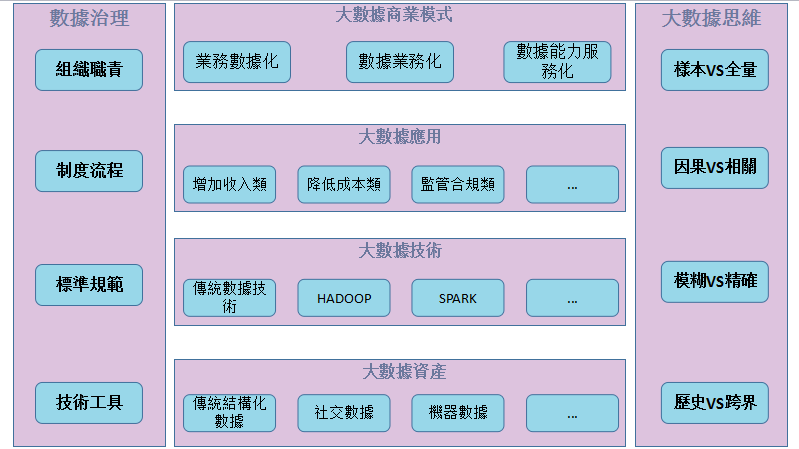
至於整體生態則表現的過於繁雜,大數據生態圈、hadoop生態圈,甚至有人一聽到生態就頭大,因為還會加上業務生態。實際上也想不到更好的描述,生態說明了這個系統的複雜性。在生態裡面的玩家很多,形形色色,各講各話。我建議還是少關心些模式、戰略,多研究些問題和技術。三年前還比較好混,比如光靠說別人聽不明白的話就可以混混;但現在不行了,理論和實踐綜合起來才可以繼續愉快的刷「存在感」。
窮理的過程中,大數據領域有一個容易陷入的誤區就是以偏概全,從一個點出發就對全局下一個判斷,諸如大數據是萬能的,或者大數據是無能的,這樣的結論看的多了自然就會厭倦。當然,還是那句話,形形色色,存在即合理,尊重每個人的觀點。
紛繁複雜的大數據生態
Matt Turck發布了最新的2017年大數據版圖,原圖很大就不浪費流量了。大數據生態圖譜中包括889家公司/產品,具體分布如下。首先要了解整體布局,然後有時間可以逐個走一遍,挑感興趣再查查資料,這樣就能了解整體生態的基本情況了。如同學科交叉的發展,今年大數據生態裡面包含了更多AI的內容;數據科學、機器學習、人工智慧,是大數據分析軟體發揮價值的關鍵。
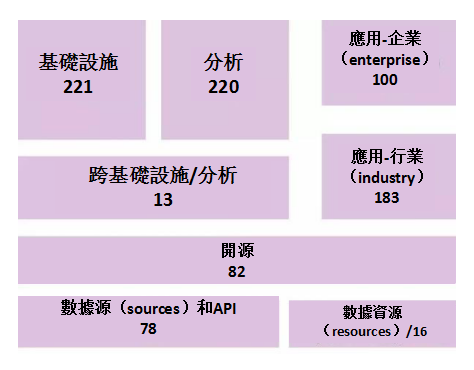
ps1: 高清版下載地址——http://mattturck.com/wp-content/uploads/2017/04/Big-Data-Landscape-2017-Matt-Turck-FirstMark.png
ps2: 圖片上具體產品的說明需要到明細網址查看,並非所有的內容都畫到了圖上。
基礎設施領域主要是多了一個Data Governance,領頭羊是Informatica和IBM。
難道大家建了一堆數據湖之後開始關心治理了,不得而知。另外最近的熱點是Spanner及其開源版本CockRoach,集成sql和nosql的優勢,很神奇。還有就是銀行常用來與TD edw配套的GreenPlum,歸屬於Cloud EDW;查了查資料,大概是MPP已經不足以反映GP的技術優勢,還加入了雲、敏捷開發等新技術。
分析這部分與2016年的版本大體一致,多了點中國元素,face++和Mobvoi。
應用部分更加細化,金融部分居然包括三個單元,不愧為大數據的頭號炒作行業。
開源部分也進一步細化了,尤其是增加了AI/DL單元。
大數據挖掘的昨天、今天和明天
數據挖掘是大數據發揮價值的關鍵,如果企業沒有成功的數據分析挖掘,那無論如何是不該說已經具備大數據能力的。以反欺詐挖掘建模為例,聊聊大數據挖掘的發展,也就是過去、現在和未來。
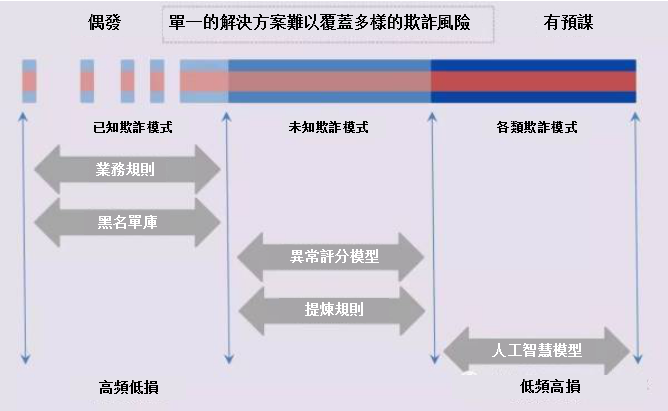
傳統反欺詐管理中主要依賴專家經驗,通過人工方式制定檢測規則,當申請或交易信息與反欺詐規則匹配後即執行相應的業務策略。這種管理模式得出的反欺詐規則存在一定的局限性,不能枚舉所有業務場景,無法對各類欺詐行為進行全面覆蓋。當專家規則積累達到一定數量後誤報率通常會比較高,能夠影響到實際風險決策制定和實際業務開展。
目前的主流做法是應用機器學習技術進行欺詐風險管理,機器學習是一種研究機器獲取新知識和新技能並識別現有知識的方法。可以結合大數據理念從整體視角對欺詐風險進行評估,實現風險的精準預測並以此作為應對欺詐風險的強力手段;同時可根據模型結果進一步提煉異常規則,發現未知欺詐模式。
未來伴隨大數據與人工智慧的持續發展,可以期待能夠識別各類欺詐模式的「真正」人工智慧模型。魔高一尺,道高一丈,模型具備自主學習和進化能力,實現欺詐風險的提前預判(想到了少數派報告)。在這個狀態下,單純的大數據已經沒有意義,替代的是一個個商業智慧解決方案,大數據和人工智慧會融入同一個生態圖譜。
大數據之路漫漫
相比之下,國內大數據行業的整體規模還不算大,說的多,做的少,掏錢的更少,整體還是起步階段。換句話說,就是killer application還比較少。插一句負責任的話,現在看到的文章和案例水分都很大;當然,不深入進去可能不太容易識別出來。
現在無論大數據治理還是大數據應用,無論諮詢公司還是實施公司,乾貨真的不多,以至於交流的時候會忍不住吐槽幾句。大數據進入銀行視野超過五年了,所以交流的時候需要乾貨,這等同於誠意的表現。踏踏實實的做點事還真不太容易,因為項目里不確定因素太多,只能確保自己盡量靠譜一點。
當然,在大數據領域,無論如何都要保持足夠的謙卑,學會選擇。在踐行過程中懂了一些,就會發現不懂的更多。從2012年開始,每年的想法都會變,所幸螺旋式的上升也會逐步到達融會貫通的境界。
原文自:SmarterBank
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!