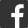目錄
很多時候,我們會發現業務資料明明非常可觀,但是最終的轉化量卻很低,高進高走,這就說明業務的轉化率有問題。而在資料分析當中,有一種至關重要的模型工具可以很好地解決這個問題,它就是漏斗模型。
什麼是漏斗分析?
漏斗分析模型,簡單來講,就是抽象產品中的某一流程,觀察流程中每一步的轉化與流失。
關於實際應用場景中漏斗模型,人們期望的無非就兩點:
1、最終漏出的數量多
2、最終漏出的比率高
針對這兩點目標,可行的措施是:
1、增加最初的流入量
2、提高每一個關鍵點的留存率
資料漏斗分析的關鍵?
一般來說,遇見的都是有序漏斗分析,這種順序體現在關鍵節點的路徑中。在有序漏斗中,路是越走越窄的,換句話說,後面的每一步留下的資料量都不可能大於前面一步留下的資料量。如果不符合這個條件,則表明關鍵路徑的流程順序可能是有問題的,需要調整路徑順序。
如何進行漏斗分析?
一、目標
像做任何資料分析一樣,漏斗分析的第一步同樣也是確定目標,也就是明白自己究竟想要做什麼,得到什麼樣的結果。比如商業行銷活動中的漏斗模型,他的目標是商業變現,獲得利潤,以此為目的確定下面五個層級:
投放廣告,提高用戶對品牌的認知,佔領用戶的心智;
觀看廣告,提高使用者對產品的興趣;
評估產品,使用者會根據對品牌的認知和產品興趣來決定是否購買;
付費購買,用戶會對評估完後感興趣的產品進行購買,達成交易;
重複購買,部分使用者會持續重複購買,也可能推薦給親戚朋友。

二、變數
變數是指能夠影響漏斗分析結果的因素,分為引數、因變數和仲介變數。
在組織行為學中,因變數是所要測量的行為反應,而引數則是影響因變數的變數。
如上邊傳統漏斗模型,因變數是廣告觀看率、商品付費率、重複購買率等,那麼廣告的投放管道(如電視、報紙雜誌、地鐵、門戶網站等)、觀看廣告的使用者年齡層次、使用者所在的區域、使用者的興趣愛好、用戶的經濟條件等就是影響因變數的引數。
仲介變數又稱為干擾變數,它會削弱引數對因變數的影響。仲介變數的存在會使引數與因變數之間的關係更加複雜。
仲介變數也就是我們需要介入的變數,需要我們去無限的進行解構,來影響引數。比如從 A 到 R (獲客 – 盈利)的轉換問題,我們可以把 A 拆分為 A1、A2、A3,再看哪一步對引數的影響比較大,假設是 A2,那麼再把 A2拆開,再看其中的主要問題。
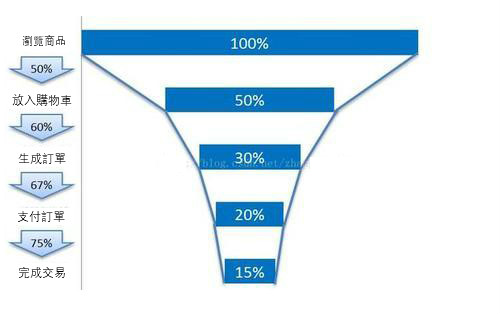
如上邊的傳統漏斗模型,假設我們的品牌為高端奢侈品,那麼我們需要對投放管道、使用者年齡層次、投放區域等進行拆分,然後發現我們的投放區域覆蓋面太多,成本比較高。
然後我們對投放地區進行拆分,發現偏遠地區投放占比比較高,那麼這個時候,我們是否找到了問題呢?我們可以收縮投放區域,有針對性的在北上廣深等這樣的大城市集中投放會不會效果更好一些呢?
最理想的狀態是,我們能夠解構到唯一變數的顆粒度。然後我們就能夠精准定位並且解決這個問題,從而帶來增長。
如果我們用的漏斗是一個很粗略的漏斗,是無法解決問題的。需要一步步解構、定位問題,然後去解決,這樣才能帶來有效的增長。
三、關係
確定了目標,確定了影響目標的各種變數之後,還需要進一步研究各變數之間的關係。
在確定變數之間的關係時,對何者為因、何者為果的判斷,應持謹慎態度。不能因為兩個變數之間存在著統計上的關係,就簡單地認為他們之間存在著因果關係。對變數間因果關係的判斷不能輕率。
比如,我們談用戶增長的時候,更多的是在談獲客,而沒有考慮如何提升現有用戶的轉化率、啟動率。我們真正需要考慮如何才能讓使用者變成忠誠用戶,只有忠誠用戶才不會流失,才能帶來更多的收益。
透過漏斗分析可以從前到後還原使用者轉化的路徑,分析每一個轉化節點的效率。
從開始到結尾,整體的轉化率是多少?
每一步的轉率是多少?
哪一步流失最多,原因是什麼?流失的使用者符合哪些特徵?
遇到巨量資料時,用什麼做漏斗分析?
如果遇到巨量資料的時候,Excel等一些工具就難以實現高效的漏斗分析了,一般的做法是用專業的數據分析工具,如FineReport搭建一個dashboard,在這上面可以輕鬆進行漏斗分析:
漏斗圖是最常用的流程分析圖表類型。透過漏斗圖可以比較直觀的查看各個環節的轉化率,從而輕鬆發現問題對應的具體環節。一個典型的漏斗圖應用是銷售漏斗。
兩種形式(連續,不連續)的漏斗圖:
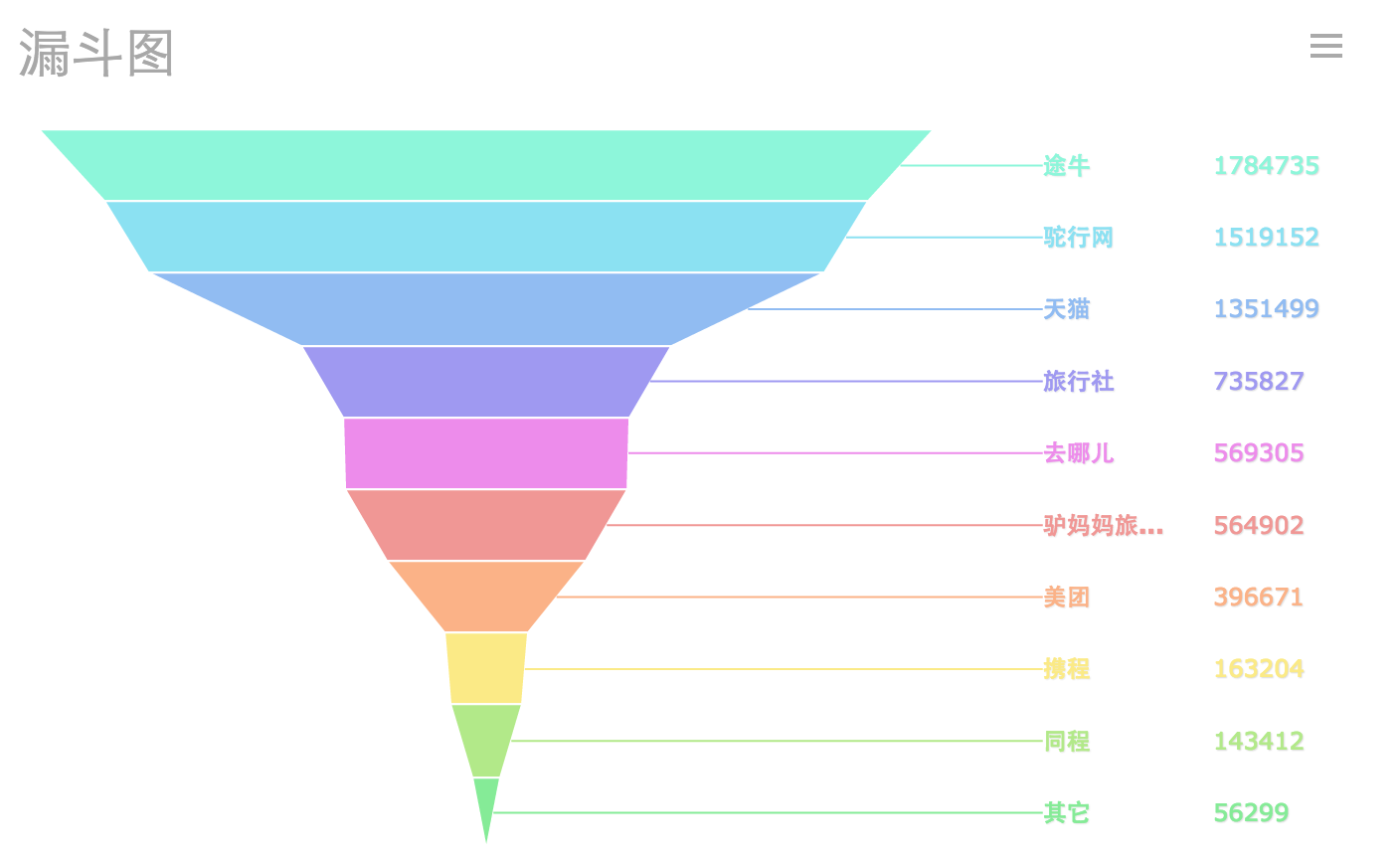
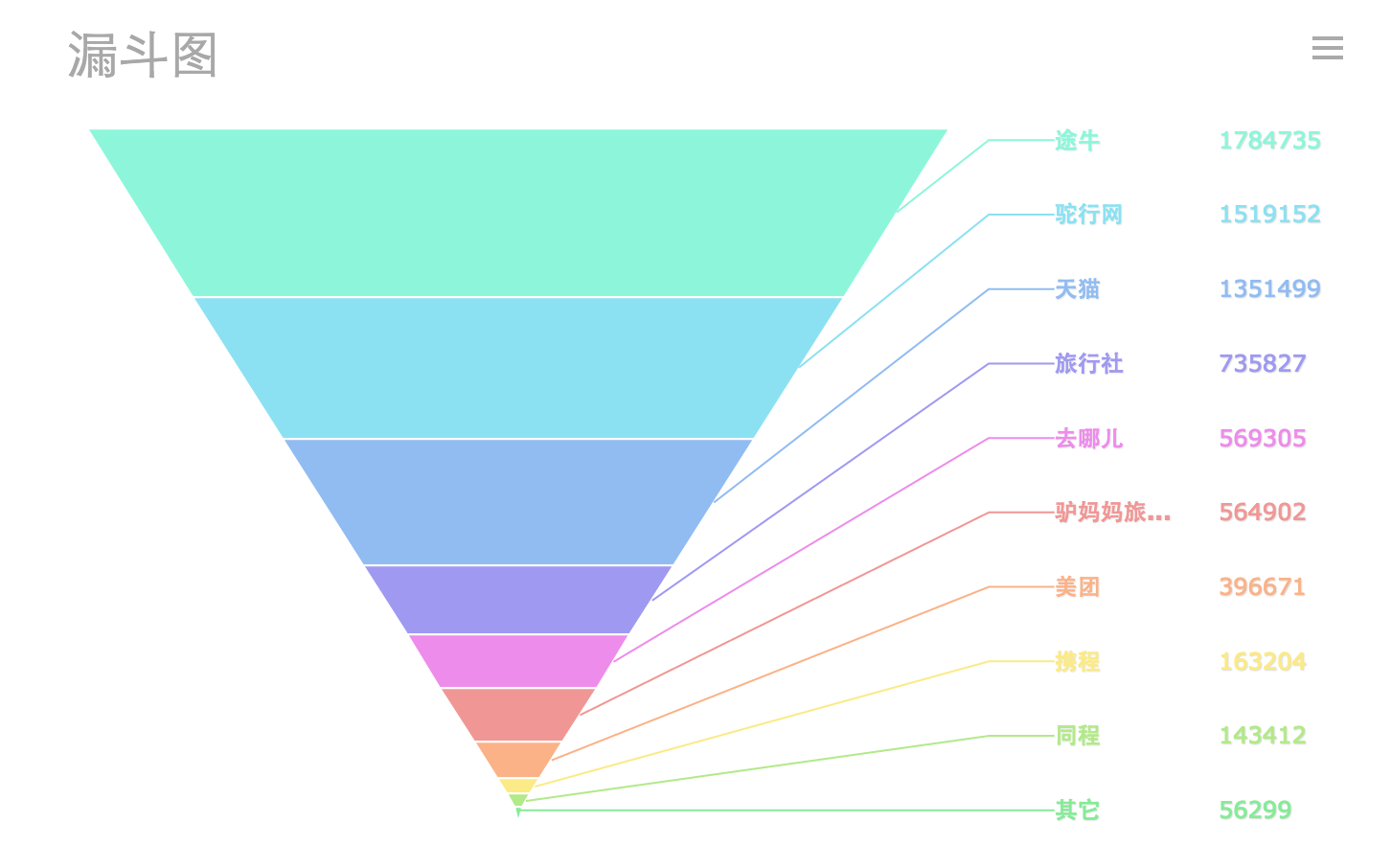
同時,FineReport的漏斗圖支援原樣展示和自動排序兩種資料展示模式。
兩種不同效果:
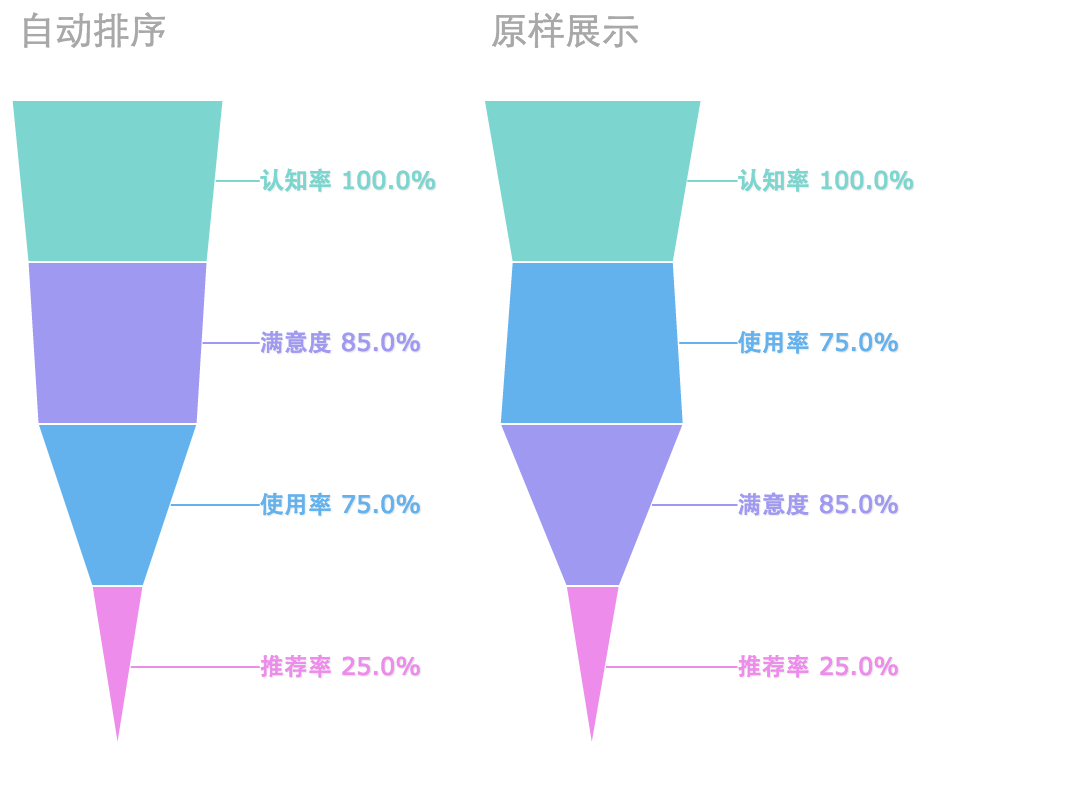
專業資料分析工具的好處就是快捷,工具本身是自帶漏斗模型的,你只需要拖拽操作就能夠完成資料漏斗分析,這一點excel等軟體是難以實現的,因此軟妹建議還是使用專業軟體。
獲得帆軟最新動態:數據分析,報表實例,專業的人都在這裡!加入FineReport臉書粉絲團!
相關文章:
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!