数据决策平台
数据决策平台
「云端运维更新」新报告、新功能,分析更全面,运维更省心!
作者:Jenny.Zhang
浏览:10,484
发布时间:2023.7.31
云端运维面世至今一年半,企业用户数已突破1400家,为了更好的协助客户达到系统的稳定和高效使用,我们对云端运维报告的版式及功能进行了优化升级,本次更新主要有以下三大亮点:
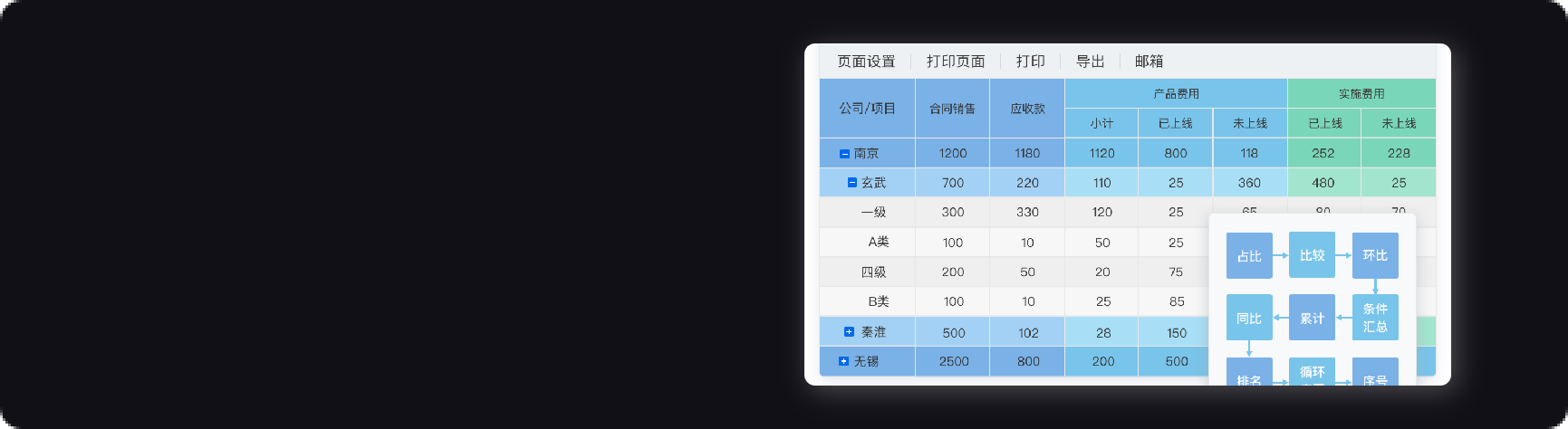
1、报告模块化分页展示
2、新增BI报告
3、内存负载评分功能上线
1丰富内容分页展示,条理更清晰
随着云端运维功能的不断增加,报告内容也更加丰富多彩,让数据分析更加全面的同时,也带来了结构不够清晰、查找关键数据困难等问题。
熟悉云端运维的用户都知道,云端运维的宗旨一直都是致力于系统的稳定和高效,那么要达到这样的效果其实是分为两个层面来着力优化的:

1、服务器层面——稳定
指的是我们使用的服务器(硬件服务器或者云服务器)以及支撑应用运行的服务器容器(如Tomcat、Weblogic等)。这些是保障我们的应用能支撑用户使用的基础,所以从运维的角度来看,我们需要关注它以下两个方向的数据
服务器运行方向:访问情况(次数、人数)、内存峰值、CPU占比峰值以及一些协助系统管理的数据(物理机内存、jdk版本、操作系统、处理器架构等)
用户体验方向:宕机情况、卡顿情况
服务器层面的数据是整个报告的第一分页(概览),通俗点说它能反映我们系统能不能正常平稳地使用。
2、应用层面——高效
指的是在服务器上安装部署的具体应用工程(如报表工程FineReport、BI工程FineBI)。这些是系统使用人员直接和系统发生交互、进行数据录入/获取/分析/价值挖掘等操作的窗口,所以从运维的角度来看,我们需要关注它以下两个方向的数据
使用效率方向:各统计单位耗时情况(模板/仪表板、数据连接、数据集等)
使用频率方向:模板访问情况(次数/人数)、日访问情况/趋势
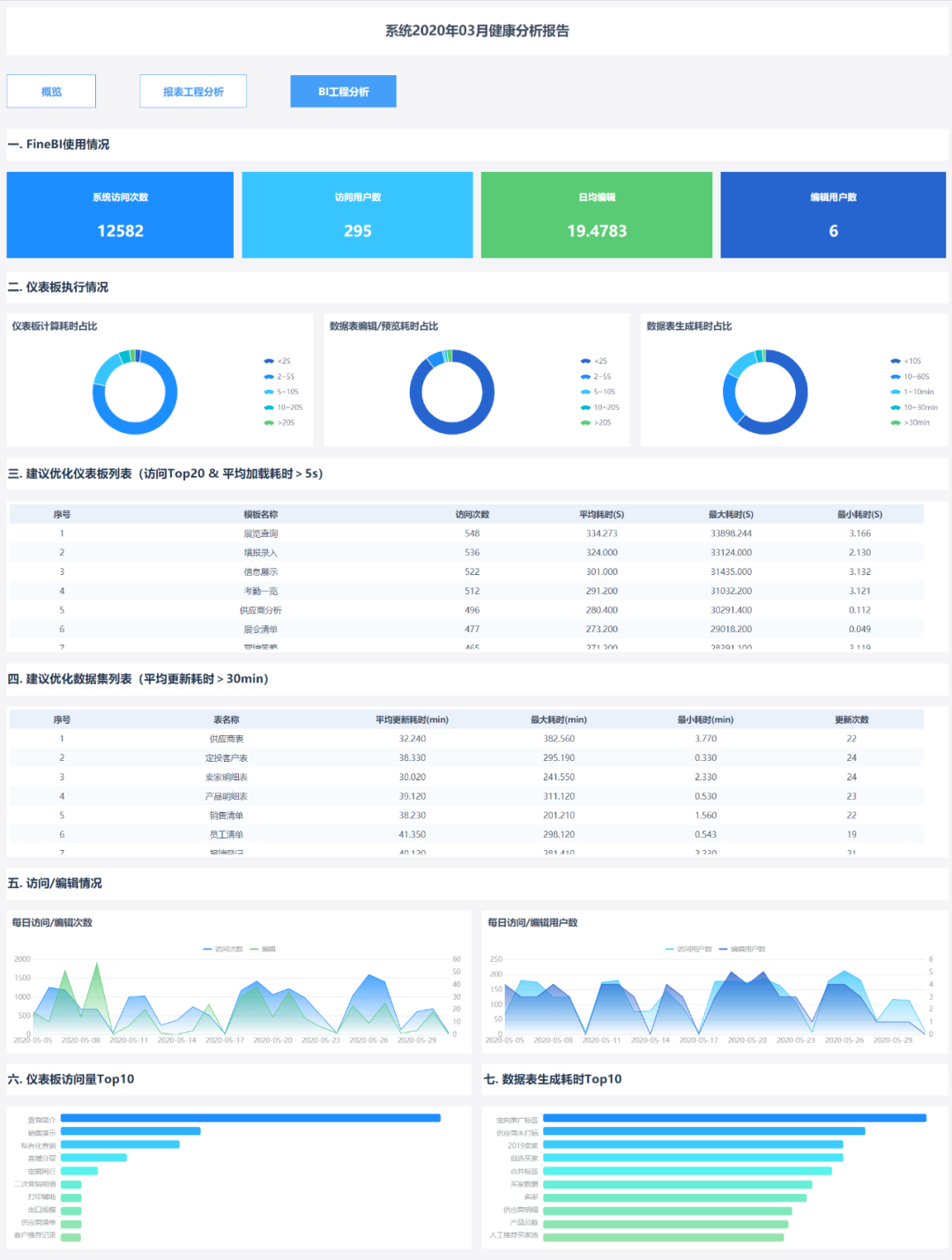
应用层面的数据是整个报告的第二、三分页(报表工程分析、BI工程分析),分别从系统易用性的理论指标和实际数据来衡量。
综合以上两个层面下的所有方向,我们在保证系统能正常平稳使用的基础上,进一步考虑系统用的多不多、用的好不好,这样才能真正实现系统的稳定和高效。
2新增BI报告,运维分析更专业
由于帆软FineReport和帆软FineBI两个产品的定位不同,其实存在很多运维层面的数据是无法拉通衡量、统一分析的,想要对系统使用情况有更精准的掌控,针对两款产品的不同特征进行精细化分析方为上上之举。
其实云端从去年开始就有此构想,今年上半年持续进行的用户调研、功能反馈中大家对BI云端运维报告的需求也验证了这个方向的正确性及必要性,如今跟随云端运维报告的版式整体升级,BI云端运维报告终于正式和大家见面啦~
1、用的多不多、好不好的衡量方式
FineReport报表工程更适用于中国式复杂报表,在企业中往往是由信息部/IT部的专业人员,在收集业务人员的需求后进行报表开发的
衡量这些报表用的多不多,更关注的是报表被业务人员访问的频次及人数
衡量用的好不好,更关注的是业务人员在访问这些报表时所需前端展示各环节的耗时情况(SQL耗时、报表计算耗时等)
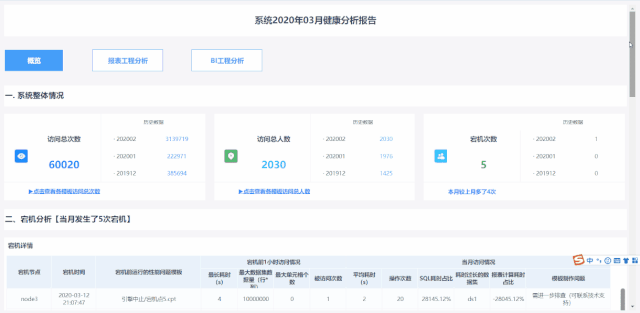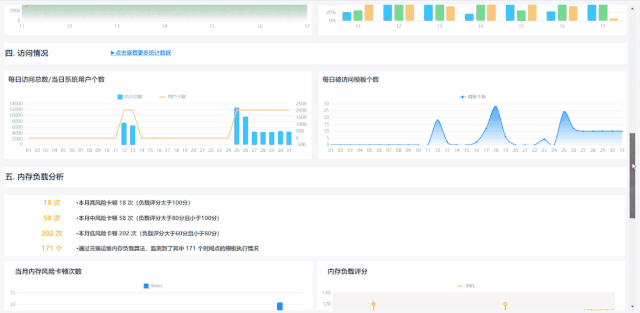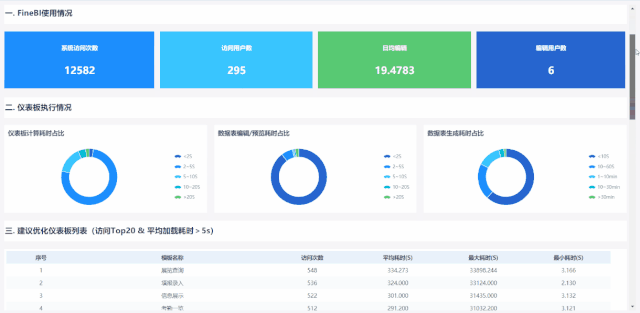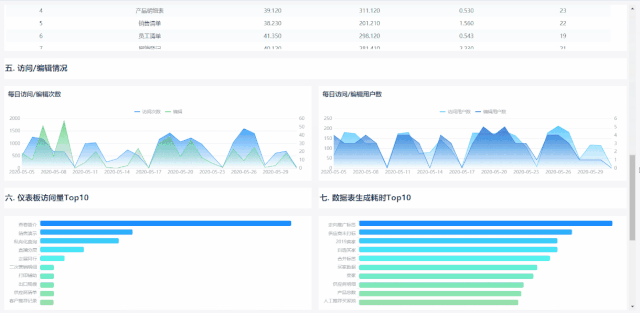
而FineBI 作为一款简单易上手自助式大数据分析工具,在应用上,区别于IT接需求开放报表模式,定位为业务用户或数据分析师基于数据需求自己做探索性分析,衡量这些仪表板的使用情况,在访问维度的基础之上,我们额外增加了编辑情况的观测维度,包括编辑用户数、日均编辑次数、编辑耗时三类数据。
从编辑用户数上,我们不仅可以直观看出使用FineBI做分析的用户总数和每日的用户数变化,还可以更深层次分析企业在一段时间内自助分析模式实现程度的高低、业务用户数据分析能力的强弱、企业内具备数据分析能力的人才储备情况等。

从日均编辑次数上,可以得到业务用户使用FineBI做数据分析的每日平均编辑次数,等价于自助分析模式下解决业务用户每日临时分析的问题数,结合编辑仪表板/数据集耗时,综合对比用excel做分析或IT帮业务开发报表模式,从而验证FineBI自助分析模式对企业的价值,是否达到了降本提效的作用。
分析举例:步步高原来只有IT一个部门为各个事业部处理数据,现在通过BI平台将分析、应用数据的部门扩展到了将近10个,编辑用户30+,为企业培养了潜在的数据分析人才,业务部门月平均编辑模版超过300次,平均每天编辑10多次,相当于每天业务自行解决了10多个即时性问题。
另外从访问层面来看,包括访问用户数和访问次数,由此计算出平均每个用户对模板的访问次数,除了可以反映出用户对数据分析结果的依赖程度,还可以反映出自助分析下业务用户自己开发的模板的价值,即平均访问次数越高,表明用户对数据分析的结果越依赖,单张模板的分析价值越高,依赖数据来决策的可能性高。

2、用的多不多、好不好的统计粒度
对FineReport的直接用户来说,整个使用流程中接触的只有报表(cpt或frm),别的一概不用管,所以此部分针对用户体验的重点关注范围就是问题模板上,那些访问频率高、且耗时长的模板是运维人员优化的重点。
但对于FineBI的用户来说,梳理完数据及关联关系后,其使用流程除仪表板外,还涉及数据集的制作(尤其是自助数据集),所以关注范围除了问题仪表板外还有问题数据集,往往及时发现一些由于误操作(如两个大数据量表之间的并集合并)导致的问题数据集并优化,其对性能的改善作用可能不亚于甚至超过改善问题仪表板的。
3内存负载评分,细致分析每一次卡顿
卡顿表现为在感知较为明显的时间里,系统没有反应、不可交互,通常过一段时间后即可自动恢复正常,但频繁地卡顿会给用户带来非常差的体验,因此卡顿问题应该和系统宕机同样受到重视。
1、为什么不重视卡顿?
数量多,人力少,系统挂起时间长
现在一般遇到宕机问题,较为有效的方式是在重启前导出系统的dump文件进行分析定位,理论上同样可以应用到卡顿问题的处理上。然而相比宕机而言,卡顿的发生频率要高出许多,系统运维人员没有足够的精力对所有卡顿情况都做如此精细的排查。退一步讲,咱不差钱,多招些人来看,那么还是有问题——导出dump期间系统是不可用的,就算人力跟得上,系统不可用的影响反而超过了卡顿带来的影响,得不偿失。
可支撑深入分析的数据少
一般遇到卡顿问题时大家第一反应是啥?“网络不好”肯定是名列前茅的答案。
不排除确实有一定比例的情况是受到网络环境影响导致前端加载的卡顿,但其实这样一个非人力可控的理由会掩盖很多问题,网络背的锅太多了。那为啥传统卡顿分析还是停留在网络环境、前端加载等浅层次分析上呢?因为缺乏支撑深入分析的数据,问题又回到了前一个导出dump的矛盾上。
卡顿体验标准不统一
上文说的“卡顿表现为在感知较为明显的时间里,系统没有反应、不可交互”,其实这个定义也有点模糊,“感知较为明显”存在感性成分较多。同一个访问需求,新入职的小白可能觉得20s内加载完毕就在可接受范围内了,但公司领导可能等待超过10s就想找信息部门谈话了。再加上系统的自身硬件条件的不同......有太多的干扰因素,导致系统运维者无法准确判断众多卡顿的严重程度,优先级的缺失让高效处理更加困难。
2、内存负载评分如何解决以上问题
分析过程全自动、零成本
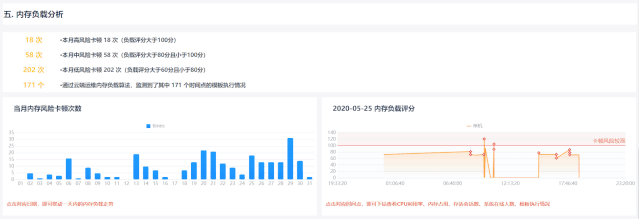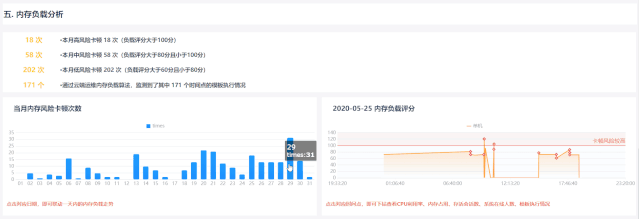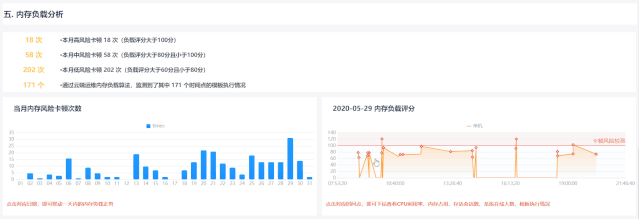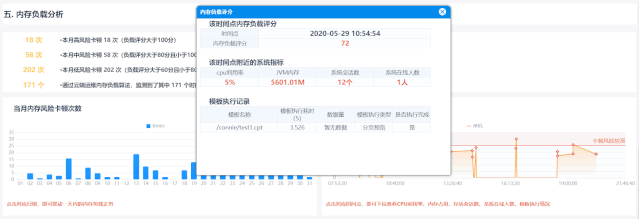
依托云端运维强大的数据分析处理能力,内存复杂评分功能根据GC日志自动关联模板执行情况,全部过程由云端运维分析,无需人力投入,且不影响系统正常使用
丰富数据支撑深入分析
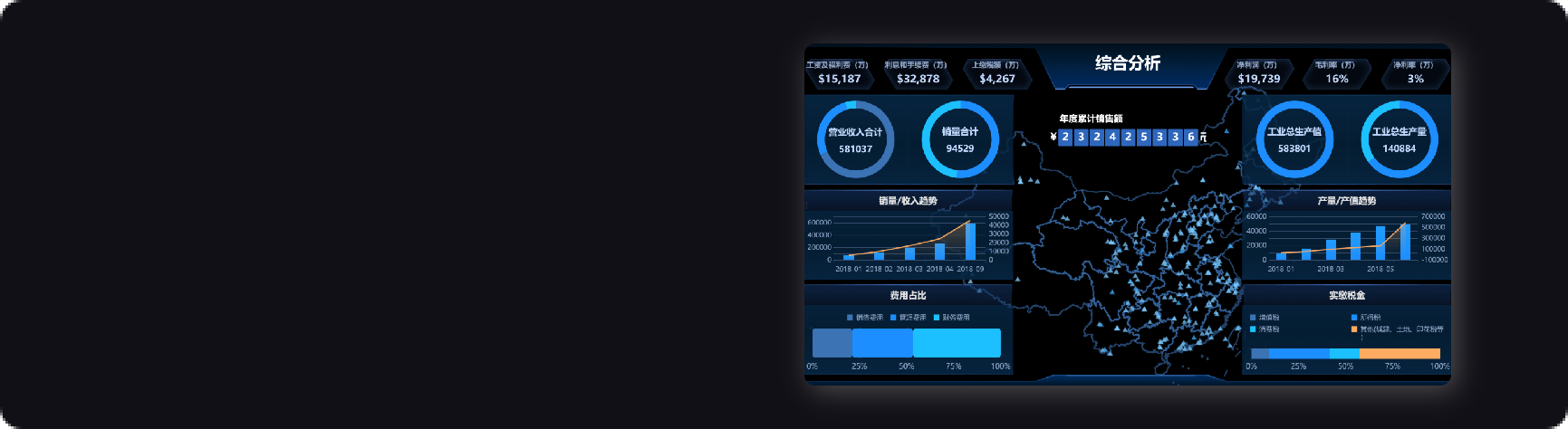
基于当前系统内存占用情况,辅以晋升量数据,综合考量系统内存负载,并且联动展示jvm内存、cpu利用率、存活会话数、系统在线人数、加载模版等,为后续分析、优化提供方向
求"同"存"异",力求衡量精确
同一报表系统内根据该时间点系统各参数对卡顿点评分,避免人为因素对衡量准确性的影响;不同系统根据其硬件配置和实时内存情况确定评分标准,具体系统具体分析,避免系统差异带来衡量标准的死板、不合理

报表工具产品更多介绍:www.finereport.com