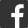目錄
最近,中國一站式外賣生活服務O2O平台「美團點評」,已經正式在香港提交上市(IPO)申請書,招股書正式曝光,目標以600億美元的估值募集60億美元資金,這也是繼小米後,今年在香港規模第二大的IPO。根據 CB Insights 數據,美團點評最新估值是 300 億美元,僅次於Airbnb成為全球排名第四最有價值的新創公司。
隨著招股書對外披露,美團的營運數字也正式曝光,以2017年來看,美團擁有3.1億用戶、440萬個活躍商家,全年交易金額為人民幣3570億元(約新台幣1.68兆元),交易筆數達58億次,2017年第四季每日平均外送交易為1470萬筆。

這樣的用戶、商家、交易數據規模,美團網是如何建構和運營起來的呢?今天我們就來一探美團網大數據平台的架構!原文是美團網大數據構建平台架構師謝語宸在大會上的分享。
1.美團大數據平台的架構
1.1總體架構
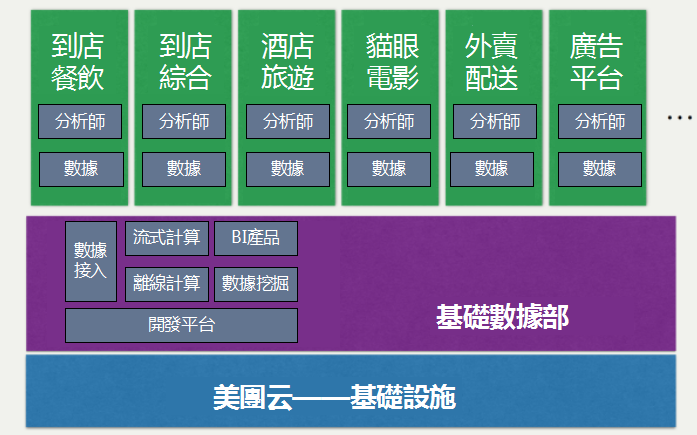
1.2數據流架構
下面我以數據流的架構角度介紹一下整個美團網數據平台的架構,最左邊首先從業務流到平台,分別到實時計算,離線數據。
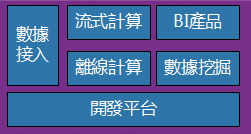
最下面支撐這一系列的有一個數據開發的平台,這張圖比較細,這是詳細的整體數據流架構圖。包括最左邊是數據接入,上面是流式計算,然後是Hadoop離線計算。
將上圖左上角擴大來看,首先是數據接入與流式計算,電商系統產生數據分兩個場景,一個是追加型的日誌型數據,另外是關係型數據的維度數據。對於前一種是使用Flume比較標準化的大家都在用的日誌收集系統,最近使用了阿里開源的Canal,之後有三個下游,所有的流式數據都是走Kafka這套流走的。
數據收集特性:
對於數據收集平台,日誌數據是多介面的,可以打到檔案里觀察檔案,也可以更新資料庫表。關係型資料庫是基於Binlog獲取增量的,如果做數據倉庫的話有大量的關係型資料庫,有一些變更沒法發現等情況,可以通過Binlog手段可以解決。通過一個Kafka消息隊列集中化分發支援下游,目前支援了850以上的日誌類型,峰值每秒有百萬介入。
流式計算平台特性:
構建流式計算平台的時候充分考慮了開發的複雜度,基於Storm。有一個線上的開發平台,測試開發過程都在線上平台上做,提供一個相當於對Storm應用場景的封裝,有一個拓撲開發框架,因為是流式計算,我們也做了延遲統計和報警,現在支援1100以上的實時拓撲,秒級實時數據流延遲。這上面可以配置公司內部定的某個參數,某個程式碼,可以在平台上編譯有調試。
離線計算是基於Hadoop的數據倉庫數據應用,主要是展示了對數據倉庫分成的規劃,包括原始數據接入,到核心數據倉庫的基礎層,包括事實和衍生事實,維度表橫跨了聚合的結果,最右邊提供了數據應用:一些挖掘和使用場景,上面是各個業務線自建的需求報表和分析庫。
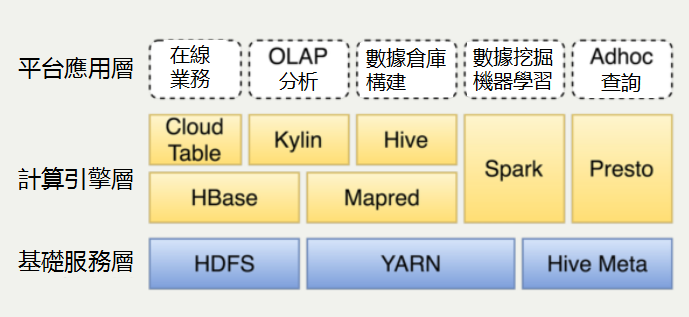
這幅圖是離線數據平台的部署架構圖,最下面是三個基礎服務,包括Yarn、HDFS、HiveMeta。不同的計算場景提供不同的計算引擎支援。如果是新建的公司,其實這裡是有一些架構選型的。Cloud Table是自己做的HBase分裝封口。我們使用Hive構建數據倉庫,用Spark在數據挖掘和機器學習,Presto支持Adhoc上查詢,也可能寫一些複雜的SQL。對應關係這裡Presto沒有部署到Yarn,跟Yarn是同步的,Spark是on Yarn跑。
離線計算平台特性:
目前42P+總存儲量,每天有15萬個Mapreduce和Spark任務,有2500萬節點,支援3機房部署,資料庫總共16K個數據表,複雜度還是比較高的。
1.3數據管理體系
數據管理體系特性:
數據管理體系主要包括自研的調配系統,數據質量的監控,資源管理和任務審核以及開發配置中心等等,之後這些都會整合到整個的數據開放平台。
數據管理體系主要實現了這樣幾點功能,
第一點是基於SQL解析做了ETL任務之間的自動解析。
基於資源預留的模式做了各業務線成本的核算,整體的資源大體是跑到Yarn上的,每個業務線會有一些承諾資源、保證資源,還可以彈性伸縮,裡面會有一些預算。
工作的重點,對於關鍵性任務會註冊SLA保障,並且包括數據內容質量,數據時效性內容都有一定的監控。
這是解析出來的依賴關係,紅色的是展示的一條任務,有一系列的上游。這是我們的資源管理系統,可以分析細到每個任務每時每刻的資源使用,可以聚合,給每個業務線做成本核算。
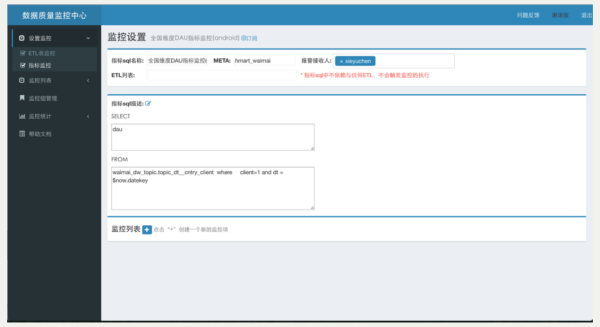
這是對於數據質量管理中心,上面可以寫一些簡單的SQL,監控某一個表的數據結果是否符合我們業務的預期。下面是數據管理,就是我們剛剛提到的,對每個關鍵的數據表都有一些SLA的跟蹤保障,會定期發日報,觀察他們完成時間的一些變動。
1.4關於BI產品

BI系统是基於數據應用平台化的場景。查詢部分主要通過一個查詢中心來支援,包括Hive,MySQL,Presto,Kylin等引擎,在查詢中心裏面我們做SQL解析。前面是一系列的商業智慧BI產品,目前大部分是自研,面向用戶可以直接寫SQL的自主查詢,並且看某一個指標,某一個時間段類似於online的數據分析產品,以及給BOSS們看的天機系統。還有指標提取工具,和商用oneline前端分析引擎設計是比較類似的,選取維度範圍,還有適時的計算口徑,會有一系列對維度適時的管理。數據內容數據表不夠,還會配一些dashboard。
在前端分析方面,我們開發了星空展示中心,可以基於前面指標提取結果,配置一系列的餅圖、線圖、柱狀圖,去拖拽,最後構建出一個dashboard,功能同市面上的其他商業智慧BI軟體類似。
2.平台演進時間線
2.1 平台發展

最開始美團網開展數據這方面的工作的時候是2011年,當時的數據統計都是基於手寫的報表,就是來一個需求我們基於線上數據建立一個報表制作頁面,寫一些表格。久而久之便跟不上管理模式了。首先是內部資訊系統的工作狀態,並不是一個垂直的,專門用做數據分析的平台,這個系統當時還是跟業務去共享的,跟業務的隔離非常弱,跟業務是強耦合的,而且每次來數據需求的時候都要有一些特殊的開發,開發周期非常長。
面對這個問題我們做了一個目前來看還算比較好的決策,就是重度依賴SQL。對SQL分裝了一些報表工具,對SQL做了etl工具。主要是在SQL層面做一些模板化的工具,支援時間等變數。這個變數會有一些外部的參數傳遞進來,然後替換到SQL的行為。
在2011下半年,我們引入了整個數據倉庫的概念,梳理了所有數據流,設計整個數據體系。做完了數據倉庫整體的構建,發現整體的ETL被開發出來了。首先ETL都是有一定的依賴關係的,但是管理起來成本非常高,所以自研了一個系統。另外發現數據量越來越大,原來基於單機MySQL的數據解析是搞不定的,所以2012年上了四台Hadoop機器,後面十幾台,到最後的幾千台,目前可以支撐各個業務去使用。
2.2 最新進展
我們也做了一個非常重要的事就是ETL開發平台,原來都是基於Git倉庫管理,管理成本非常高,當時跟個業務線已經開始建立自己數據開發的團隊,我們把他們開發的整個流程平台化,各個業務線就可以自建。之後遇到的業務場景需求越來越多,特別是實時應用。2014年啟動了實時計算平台,把原來原有關係型數據表全量同步模式,改為Binlog同步模式。我們也是在國內比較早的上了Hadoop2.0 on Yarn的改進版,好處是更好的激起了Spark的發展。另外還有Hadoop集群跨多機房,多集群部署的情況,還有OLAP保障,同步開發工具。
3.平台化思路總結
3.1平台的價值
作為一個平台的團隊,核心價值其實就三個:
一是對於重複的事情要做精做專;
二是統一化。可以推一些標準,推一些數據管理的模式,減少業務之間的對接成本;
最重要的是為業務整體效率負責,包括開發效率、迭代效率、維護運維數據流程的效率,還有整個資源利用的效率。
3.2平台的發展
如果才能發展成一個好的平台呢?
我理解的三點:
● 首先支援業務是第一位的,如果沒有業務我們平台其實是沒法繼續發展的。
● 第二是與先進業務同行,輔助並沉澱技術。在一個所謂平台化的公司,有多個業務線,甚至各個業務線已經是獨立的情況下,必定有一些業務線是先行者,他們有很強的開發能力、調研能力,我們的目標是跟這些先行業務線同行。
● 第三是設立規範,用積累的技術支撐後發業務。與業務一起前進的過程中,把一些經驗、技術、方案、規範慢慢沉澱下來。對於剛剛新建的業務線,或者發展比較慢的業務線,我們基本策略是設定一系列的規範,跟優先先行業務線積累去支撐後續的業務線,以及功能開發的時候也可以藉助。保持平台團隊對業務的理解。
3.3關於開源
以上談到的平台中有很多是開源的直接拿來用的,比如說,zeppelin,Kylin。
我們的策略是持續關注,其實也是幫業務線做前瞻性調研,他們團隊每天都在看數據,看新聞,他們會講新出的一個項目你們怎麼推,你們不推我們推了,我們可能需要持續關注,設計一系列的調研方案,幫助這些業務去調研,這樣調研這個事情我們也是重複的事情只干一次。
如果有一些共性patch的事情,特別一些bug、問題內部也會有一個表共享,內部有大幾十個patch。選擇性的重構,最後才會大改,特別在選擇的時候我們強調從業務需求出發,理智的進行選型權衡,最終拿出來的方案是靠譜能落地實施的方案。
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!