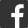在數據分析中,模型是非常有用和有效的工具和數據分析應用的場景,在建立模型的過程中,數據探勘很多時候能夠起到非常顯著的作用。伴隨著計算機科學的發展,模型也越來越向智慧化和自動化發展。對數據分析而言,了解數據探勘背後的思想,可以有助於建立更具穩定性的模型和更高效的模型。
數據探勘前世今生
數據模型很多時候就是一個類似Y=f(X)的函數,這個函數貫穿了模型從構思到建立,從調試再到最後落地應用的全部過程。

Y=f(X)建立之路
對模型而言,其中的規則和參數,最初是通過經驗判斷人為給出的。伴隨著統計方法和技術的發展,在模型的建立過程中,也引入了統計分析的過程。更進一步地,隨著計算機科學的發展,建模的過程,也被交給了機器來完成,因此數據探勘也被用到了模型的建立中。
數據探勘,是從大量數據中,探勘出有價值信息的過程。在有的地方,數據探勘也被成為是數據探礦,正如數據探勘的英文data mining一樣,從數據中探勘有價值的知識,正如在礦山中採集鑽石一般,不斷去蕪存精,不斷發掘數據新的價值。數據探勘是通過對數據不斷的學習,從中發掘規律和信息的過程,因此也被稱為統計學習或者是機器學習。對數據探勘而言,其應用範圍廣泛,除了建模,在人工智慧領域也有使用。
回到模型中,從經驗判斷到數據探勘,建立模型的計算特徵發生了極大的改變。
計算特徵的發展
首先數據的維度開始從少變多,最初只有幾個維度,到現在有上百個維度。數據的體量,即記錄的條數也從少量到海量,從過去了百條規模到了現在億條規模。伴隨著數據獲取的難度下降,數據的維度和記錄數量會越來越多。在這種情況下,數據的處理過程也越來越複雜,從過去簡單的幾次加減計算得到結果,到了現在必須要經歷上億次的複雜運算。同時,伴隨著計算性能的提升,對於從數據中提取信息而言,也從漸漸深入,過去只能發現一眼看出的淺表信息,如今可以不斷去探勘隱含的知識。
數據探勘的基本思想
數據探勘的別名機器學習和統計學習一樣,數據探勘的實質是通過計算機的計算能力在一堆數據中發掘出規律並加以利用的過程。因此對數據探勘而言,就需要經歷規則學習、規則驗證和規則使用的過程。
數據探勘的基本思想
規則學習又稱為模型訓練,在這個步驟中,有一個數據集將作為訓練集。按照相關的演算法和輸出規則的要求,從訓練集中篩選出需要使用的變數,並根據這些變數生成相關的規則。有的時候,是將過去已經發生的數據作為訓練集,在對比已知的結果和輸入的變數的過程中,以儘可能降低輸出誤差的原則,擬合出相應的模型。
當產生了規則後,就需要驗證規則的效果和準確度,這個時候就需要引入驗證集。驗證集和訓練集具有相同的格式,既包含了已知的結果也包含了輸入的變數。與訓練集不同的是,對驗證集的應用是直接將規則應用於驗證集中,去產生出相應的輸出結果,並用輸出的結果去對比實際情況,以來確定模型是否有效。如果有效的話,就可以在實際的場景中應用。如果效果不理想,則回頭去調整模型
測試集是將模型在實際的場景中使用,是直接應用模型的步驟。在測試集中,只包含輸入變數卻沒有像其他兩個數據一樣存在的已知結果。正因為結果未知,就需要用測試集通過模型去產生的輸出的結果。這個輸出結果,將在為結果產生以後進行驗證,只要有效,模型就會一直使用下去。
數據探勘的流程
數據探勘與數據分析的流程相似,都是從數據中發現知識的過程,只不過由於數據體量和維度的原因,數據探勘在計算上最大。

數據探勘的流程
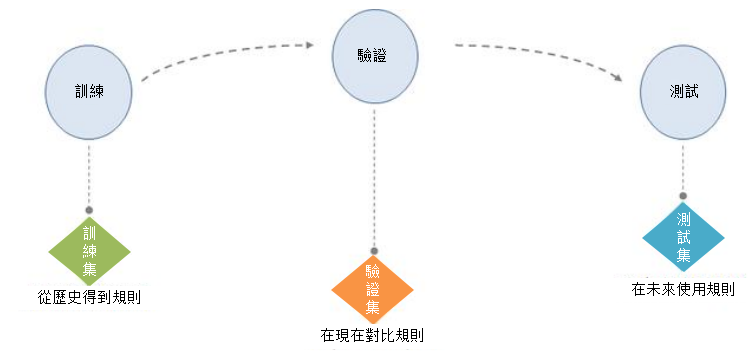
對數據探勘而言,首先是進行數據獲取,數據獲取的來源很多,有系統中自行記錄的數據,對這種數據只要導出即可,同時也有外來數據,比如網頁爬取得數據,或者是購買的數據,這些數據需要按照分析系統的需求進行導入。
在完成了數據獲取步驟後,就需要進行數據處理,數據處理即是處理數據中的缺失值,錯誤值以及異常值,按照相關的規則進行修正或者刪除,同時在數據處理中也需要根據變臉之間的關係,產生出一系列的衍生變數。總而言之,數據處理的結果是可以進行分析的數據,所有數據在進行分析以前都需要完成數據處理的步驟。
如果數據在分布上存在較極端的情況,就需要經曆數據平衡的不走。例如對於要輸出的原始變數而言,存在及其少量的一種類別以及及其大量的另一種類別,就像有大量的0和少量的1一樣,在這種情況下,就需要對數據進行平衡,通過複製1或者削減0的形式生成平衡數據集。
當完成數據平衡後,將會把數據處理的結果分出一部分作為驗證集使用,如果數據平衡性好,那麼剩下的部分作為訓練集,如果平衡性不好,那麼平衡數據集就會作為訓練集使用。當有了訓練集後,就按照相關的演算法對訓練集進行學習,從而產生出相關的規則和參數。當有了規則以後,就將產生的規則用在驗證集中,通過對比已知結果和輸出結果之間的誤差情況,來判斷是否通過。如果通過則在後面再測試集中使用,如果未通過,就通過數據平衡、參數調整,以及變數選擇等手段重新調整規則,並再次進行驗證,直到通過驗證。
對於驗證集驗證的步驟而言,在無監督學習中沒有這個步驟,當纏上規則後,就直接用於測試集。
數據探勘周而復始
數據探勘是一個周而復始的過程,在生成規則的過程中,不斷地對模型進行調整,從而提升精度。同時也將多批次的歷史數據引入到數據探勘的過程中,進行多次的驗證,從而在時間上保證模型的穩定性。
數據探勘的模式
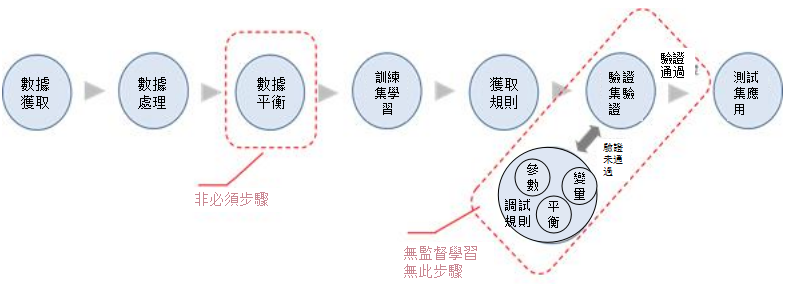
在數據探勘中,對於規則的獲取,存在三種方式,分別是監督學習,無監督學習和半監督學習,這三種方式都是通過從數據的統計學習來制定規則。
在一個數據探勘問題中,變數可以分為自變數和因變數,規則是以自變數為輸入,以因變數為輸出的結果,由此對數據探勘問題,就把自變數定義為X,把因變數定義為Y。
獲取規則的方式,來源於對數據的統計學習
對於監督學習而言,訓練集中包括了自變數X和因變數Y,通過對比X和Y的關係,得除相應的規則,同時再在驗證集中,通過輸入驗證集的自變數X,藉助規則得到因變數Y的預測值,再將Y的預測值與實際值進行對比,看是否可以將模型驗證通過,如果通過了,就把只包含自變數X的測試集用於規則中,最終輸出因變數Y的預測值。在監督學習中,因變數的實際值和預測值的對比,就起到監督的作用,在規則制定中需要盡量引導規則輸出的結果向實際值靠攏。
對無監督學習而言,訓練集中,就沒有包含因變數Y,需要根據模型的目標,通過對自變數X的分析和對比來得出相關的規則,並能夠產生合理的輸出結果,即Y,在制定規則的過程中,需要有一些人為的原則對規則進行調整。當完成調整後,就可以把只包含自變數X的測試集放到規則中,去產生規則的結果Y。
對比監督學習和無監督學習,最大的區別就是,在制定規則的過程中,是否有Y用於引導規則的生成。監督學習中,有Y存在,生成規則過程中和生成規則時,也會對比Y的預測值和實際值。而在無監督學習中,就沒有Y作為對比的標準,相應的規則都直接由X產生。
半監督學習,與監督學習類似,也需要因變數Y參與到規則生成和規則驗證中去。但是在訓練集只用只有一少部分的對象既有自變數X和因變數Y,還有大部分對象只包含了自變數X。因此在對半監督學習的規則生成中,需要有一些特殊的手段來處理只包含的自變數X的對象後,再生成相關的規則。在後面的驗證和測試的流程都與監督學習一致。因而對於半監督學習,最重要的問題就是如何藉助少量的因變數Y而產生出可以適用的規則。
數據探勘的應用場景
數據探勘應用的場景很多,通常有四種情況被廣泛的使用。

數據探勘的應用場景
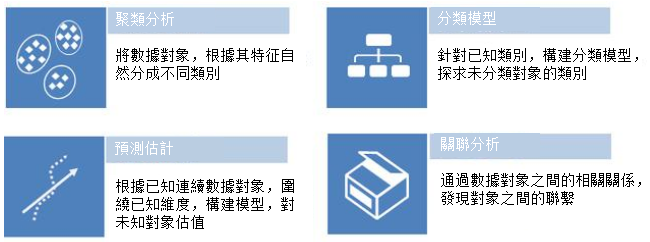
首先是聚類分析,就是將不同的對象,根據其變數特徵的分布自然地分成不同的類別。此外是分類模型,這是針對已知的類別,構建出分類的模型,通過分類的模型來探求其他未分類對象的類別。第三是預測估計,集根據對象的連續數據因變數,通過圍繞已知的維度,構建出預測因變數的模型,從而對因變數未知的對象進行估計。最後是關聯分析,即通過探求數據對象之間的相關關係,來發現對象之間的聯繫,在關聯分析中,更多是以對象之間的關係作為輸出。
聚類分析
聚類分析是一種無監督學習的數據探勘方法,其目的是基於對象之間的特徵,自然地將變數劃分為不同的類別。在聚類分析中,基本的思想就是根據對象不同特徵變數,計算變數之間的距離,距離理得越近,就越有可能被劃為一類,離得越遠,就越有可能被劃分到不同的類別中去。
聚類分析基本思想
例如在坐標系中,B距離A的距離遠遠小於,B到C的距離,因此,AB更容易劃分為一類,而BC更容易為不同的類別。通常來說,一個對象距離同類的距離是最近的,都小於其他類別中對象的距離。
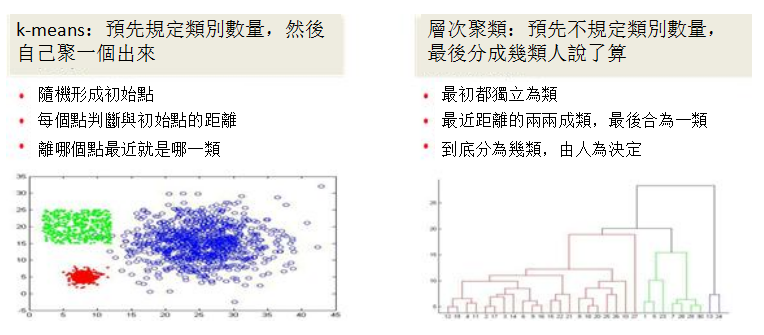
在聚類分析中,有兩種常用的方法,一種是K-means聚類,一種是層次聚類。
K-means聚類VS層次聚類
在K-means聚類中,是預先規定出要產生多少個類別的數量,再根據類別數量自動聚成相應的類。對K-means而言,首先是隨機產生於類別數相同的初始點,然後判斷每個點與初始點的距離,每個點選擇最近的一個初始點,作為其類別。當類別產生後,在計算各個類別的中心點,然後計算每個點到中心點的距離,並根據距離再次選擇類別。當新類別產生後,再次根據中心點重複選擇類別的過程,直到中心點的變化不再明顯。最終根據中心點產生的類別,就是聚類的結果。正如圖中所示,一組對象中需要生成三個類別,各個類別之間都自然聚焦在一起。
在層次聚類中,不需要規定出類別的數量,最終聚類的數量可以根據人為要求進行劃分。對層次聚類,首先每個對象都是單獨的類別,通過比較兩兩之間距離,首先把距離最小的兩個對象聚成一類。接著把距離次小的聚成一類,然後就是不斷重複按距離最小的原則,不斷聚成一類的過程,直到所有對象都被聚成一類。在層次聚類中,可以以一張樹狀圖來表示聚類的過程,如果要講對象分類的話,就可以從根節點觸發,按照樹狀圖的分叉情況,劃分出不同的類別來。在圖中,把一組對象分成了三個類別,可見這三個類別就是構成了樹狀圖最開始的三個分支。
聚類分析的過程,和分桔子其實很很像,人們通常都把特徵相同的桔子分成一類,聚類分析中,也是同樣的方式。
聚類分析案例
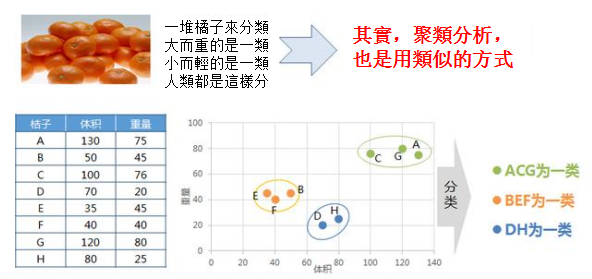
正如在這個例子中,有A-H的8個桔子,對每個桔子而言有提體積和變數兩個變數。通過將各個桔子投射到重量和體積構成的坐標系中,可以發現BEF距離很近,ACG距離很近,而DH距離很近。如果聚成3類的話,可以是ACG、BEF,DH各為一類。如果是聚成兩類,BEFDH與ACG相對更近,因此可以是ACG為一類,而BEFDH為另外一類
分類模型
分類模型通常是通過監督學習產生的,根據已知的對象的類別和其具體特徵特徵的數據,通過訓練從而產生由特徵判斷類別的規則。在分類模型中,規則的輸出就是具體的類別。
分類模型基本思想
分類模型的規則產生的過程中,類別判別的原則與訓練集中各特徵變數的分布息息相關,通常就是在對比各個類別下特徵變數的互相關係,而劃分出相關的規則,這個過程遵循的原則就是儘可能讓輸出的類別與實際的類別保持一致。
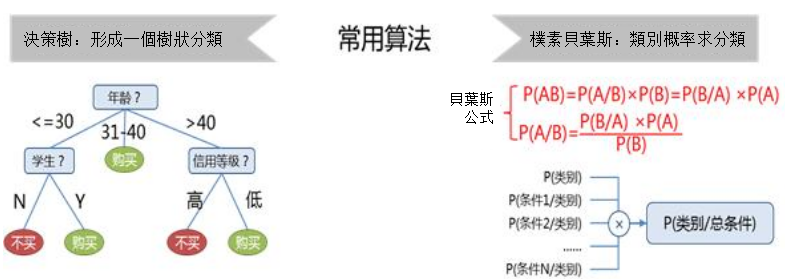
當前,不管在學術研究領域還是業務應用領域都有大量的分類模型,通常來說,決策樹和樸素貝葉斯是非常普遍的分類模型演算法,這兩個演算法在一些文獻中也被列為十大數據探勘演算法。

決策樹VS樸素貝葉斯
決策樹的規則生成演算法是將對象按照相關的特診變數進行依次拆分,在拆分中不斷迭代條件,最終劃分為最終的類別。決策樹的劃分過程,就像是一個樹一樣,從根節點觸發,依次開支散葉,最終形成分類準則。
在圖中,首先就按照年齡進行分支,直接將所有對象分成了三堆,其中年齡在31-40歲的被劃定為購買類,另外的兩堆對象,還需要繼續進行分支。對年齡小於30歲,按照是否為學生進行分支,其中是學生的被判定為購買類,不是學生的被判定為不買類。同樣對年齡大於40歲,按照信用等級進行分類,信用等級高的被判定為不買類,信息等級低的被判定為購買類。就這樣,任何一個對象,都可以根據條件達成的情況,最終到達購買或者不買的節點,完成分類過程。
樸素貝葉斯的規則生成演算法相對決策樹而言,就沒有這麼直觀了,其依賴於概率中的貝葉斯公式。由公式P(AB)=P(A/B)×P(B)=P(B/A)×P(A)得來的後驗概率公式P(A/B)=P(B/A)×P(A)/P(B),其中A類別,B表示條件即特徵變數。P(A/B)表示在特定條件下該類別的概率,P(B/A)表示在特定類別下該條件的分布概率,P(A)表示已知的特定分類的概率,而P(B)表示已知的特定條件的概率。
在演算法中,P(B/A)、P(A)、P(B)都通過訓練集能夠得到,再加上在條件一定時,P(B)是恆定的,同時每個條件互相獨立,根據概率公式,P(類別/總條件)是P(類別)和所有P(條件/類別)的乘積。因此在樸素貝葉斯中,最大的P(類別/總條件)對應的類別,就是被劃分的類別。
最近這幾年,網上總有要遠離女司機的段子,在網友心中女司機簡直如洪水猛獸一般,這種說法一方面來自於個別事例的傳播,另外一方面也來自於女司機在低速駕駛時對他人的困擾造成的誤解。其實,對於女司機是不是應該害怕的問題,就可以用分類模型的解決。
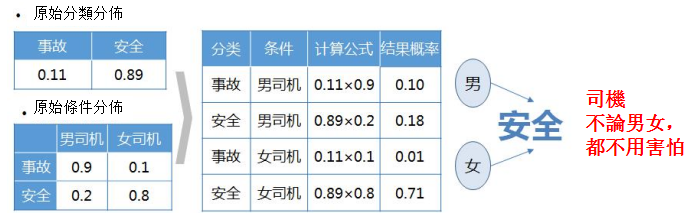
用分類模型解決女司機問題
已知道路上的車輛中的分布如下,會發生的事故的概率有0.11,而是安全的概率有0.89,車輛的分布就是對事件的原始分類分布。同時,對發生條件的分布如下,發生事故時,男司機概率為0.9,女司機概率為0.1,在安全情況下時,男司機概率為0.2,女司機概率為0.8。

分類模型案例計算流程
那麼根據貝葉斯公式,可以知道,當遇到男司機時,發生事故的概率為0.1,而女司機是0.01,兩者的事故的概率都很低。對男女司機而言,其發生事故的概率都低於安全的概率,因此在職考慮性別的情況下,所有司機都是被分為安全類別,尤其是女司機,安全的概率遠遠大於事故。因此不能簡單的通過司機的性別,就做出是否危險的判別,尤其是遇到女司機。
關聯分析
關聯分析模型常用於揭示事件之間的關係,是通過無監督學習的方式,產生的輸出事件之間發生關係的規則。關聯分析最開始在零售領域常常用到,比如可以提供買了速食麵時很多情況都會買火腿腸的關係,因此在某些情況下,關聯分析又被稱為購物籃分析。

關聯分析基本思想
在購物籃分析中,其核心思想就是對比單個事件發生的概率,和多個事件同時發生的概率的情況,如果同時發生的概率與單獨發生的概率相近,則可以考慮發生了一個事件後,很有可能會存在同時發生另外一個事件的情況。
有事件X和事件Y,以及XY同時發生的概率,在購物籃分析中,支援度是XY同時發生的概率,置信度是當X發生了,Y也發生的條件概率。

關聯分析演算法
如果在規則中,兩個事件的支援度和置信度都達到了制定的閾值,則可以認為這兩個事件具有強關聯的關係。關聯分析正是體現了這種強關係。在強關係中,還有提升度來確認這種強關係的力度,提升度是指,當X出現同時出現Y的概率,與Y總體出現的概率之比,即X對Y的置信度與Y發生概率的比值,通常來說提升度都是大於1的,提升度越大,說明強關係力度越大。
在關聯分析中,強關係存在兩種情況,這種情況具有不同的時間上的考慮,第一種是序列關係,即事情順次發生,比如購買了A了以後又繼續購買B,另外一種是同時關聯,即事件同時發生,比如買了A的同時也買了B。
啤酒和尿布是關聯分析中的經典案例,儘管最近出現了這個只是編造的案例而已,然而去仍然能體現出關聯分析的價值出來。
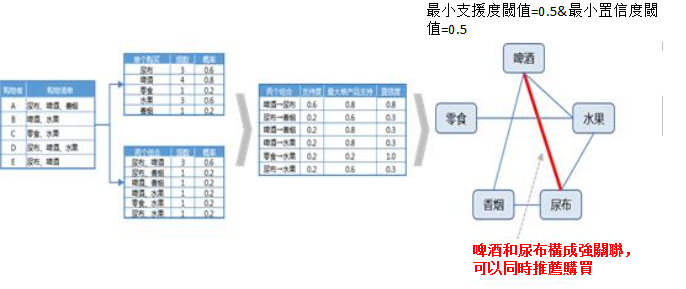
在啤酒和尿布中發現關聯分析的價值
啤酒和尿布,兩個看起來不無相關的物品,卻可以通過關聯分析,找出進行同時銷售的機會出來,其背後的原理就是發現了,啤酒和尿布之間的強關聯關係。

關聯分析案例計算過程
假設有尿布,啤酒,零食,水果和香煙的五種商品,同時也知道了各個商品購買的清單,根據清單可以提取單個產品的頻數和其對應的概率,以及產品之間兩兩組合帶來頻數和概率。根據支援度和置信度的計算公式,可以得到,每個產品組合的支援度,以及置信度。設置強關聯最小支出度閾值以及最小置信度閾值都為0.5時,啤酒對尿布達到了強關聯的閾值,因此啤酒對尿布這對組合可以認為具有強關聯,因此在購買啤酒時推薦購買尿布,能夠增加尿布的銷量。
預測估計
預測估計的規則,是用來輸出連續的數值,即通過預測估計的規則,模型輸出的是系列的數值,這些數值可以進行加減乘除的一系列計算。

預測估計基本思想
預測估計的規則通常以一個公式存在,這個公式可以體現出要輸出的因變數Y與特徵變數X的關係,最簡單的來說,像一條在坐標系反應Y和X關係的直線一樣,知道了X是多少的情況,就可以根據線性關係,輸出對應的Y。這種思路正式用於生成回歸方程,因此有的時候預測估計也被稱為是回歸。
在預測估計中,首先是對比訓練集中要輸出的因變數Y和特徵變數X的關係,通常來說,X不只有一個,而是有X1,X2,X3,Xn等多個,在這種情況下,通過學習X1到Xn與Y的數學關係,從而產生出能夠基於X1到XN預測出Y的規則。如果規則通過驗證集的驗證,就可以在實習情況中與預測要輸出的因變數Y。

預測估計演算法
預測估計的輸出變數可以是絕對值也可以是相對值,在輸出絕對值的情況下,線性回歸是常用的模型,即生成一條關於Y與X1到Xn的直線方程,用來預測Y。在輸出相對值得情況,邏輯回歸是常用的模型。在邏輯回歸中,輸出的Y是概率,在規則中通過擬合X的直線,產生出一個結果,再將直線輸出結果進行指數化轉換,最終結果就是的Y,即事件發生概率。
下面是一個用預測估計的模型來預測誰可以得獎的例子,在這個例子中,並不是直接用模型預測得獎的人員,而是通過對過去得獎的人員的數據進行學習,從而得出計算得獎概率的規則,並通過學習到的規則,根據本次所有人的表現的數據,來預測各自的將概率。
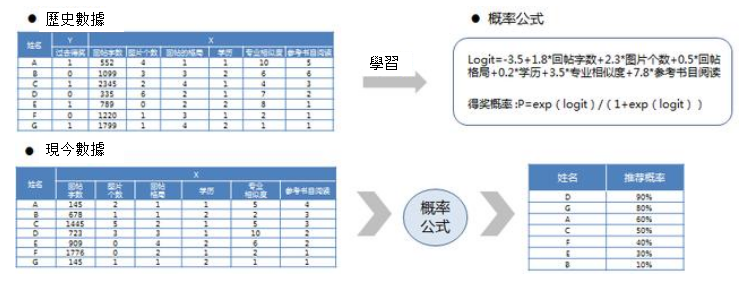
用預測估計知道得獎概率
在這個例子中,共有7個變數,其中過去得獎是作為0-1因變數存在,1表示得獎,0表示未得獎。在自變數中有另外6個變數。通過對歷史的數據的學習,能夠得到logit的計算公式,並根據概率換算的公式,得到概率的公式。
學會數據分析背後的探勘思維,分析就完成了一半!
再進一步地,取得當前數據後,根據概率公式,得到每個人為的得獎概率,概率最大的即為最可能得獎的人。
探勘思維總結
在探勘思維是與數據探勘相關,相比前面幾種思維而言,探勘思維似乎要晦澀難懂一些,畢竟數據探勘涉及的已經不局限於簡單的數學,而且還擴充到了計算機科學層面。這裡設置探勘思維,其目的就是在解答,當數據量實在太大時,維度實在太多時,應該如何來處理的問題。
探勘思維總結
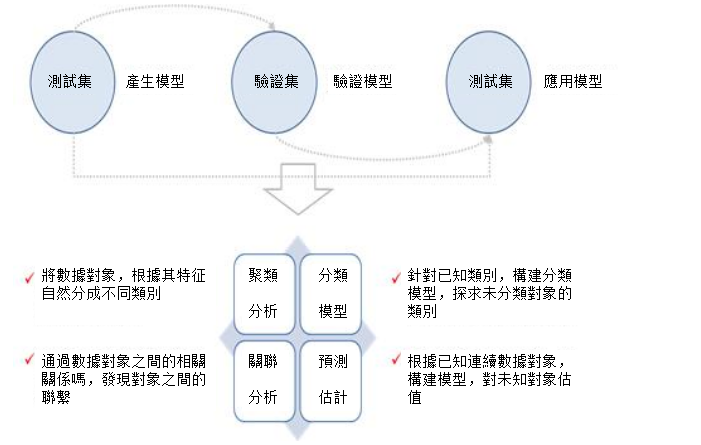
數據探勘的實質,其實還是為了得到一個模型,產生結果。當數據需要特別複雜的計算過程時,數據探勘就能夠產生作用了。數據探勘通常通過已知輸出的結果的數據中作為訓練集產生出模型,再用另外一部分知道已知輸出結果的數據作為驗證集來驗證模型的可信程度,通過驗證後,再用到測試集中去取得實際的效果。
數據探勘分為四種類型,就像前面所述,四種類型分別是聚類分析、分類模型、關聯分析和預測估計。聚類分析是將數據對象,根據其特徵自然分成不同類別。分類模型是針對已知類別,構建分類模型,探求未分類對象的類別。關聯分析是通過數據對象之間的相關關係,發現對象之間的聯繫。預測估計就是根據已知連續數據對象,構建模型,對未知對象估值。
舉一個簡單的例子,知道一個班之間學生平時作業的情況,將學生自動分成若干類別,就是聚類分析,這些有可能是學霸型,學渣型,還有可能是偏科型,到底類別怎麼樣,事前都不知道,要聚類以後才知道。已知一部分學生的類別,而不知道另外一部分學生,就用分類模型的方式得出另外一些學生的類別。知道一些學生掛語文的同時還容易掛哪些學科,就是關聯分析。從學生平時作業來預測他們期末考試分數就是預測估計。
文:keeya
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!