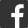本文是我關於大數據分析方法的幾點思考。當初的目的是系統化地看待數據分析。為了這點東西,我花了一個禮拜的時間,思考的結果卻是碎片化的。看來,想清楚並不容易。由於時間關係,只能中止。文字描述很不嚴格、肯定經不起推敲,讀者找不毛病是正常的、看不明白更是正常的。不感興趣的可以當做胡扯。我希望將來有時間時能把問題思考下去。
從數據中發現信息和知識,是人們多年來的夢想。隨著大數據理論的興起,這個話題變得非常熱門。在有些人看來,大數據分析軟體非常神秘,似乎無所不能。當然,現實不會是這樣。我想,研究大數據,首先要破除迷信:大數據需要什麼條件、什麼問題是大數據無法做到的。
1、知識和信息,只能從關聯關係中得到
對象(包括過程,如生產過程、購物過程)及其屬性、同一對象的屬性之間具備關聯關係。例如,「張三身高1.8米」就是對象(張三)與屬性(身高)的關聯;再如,如果我們知道張三體重75公斤,則「1.8米」和「75公斤」之間就因「張三」建立了關聯。
關聯的對象可能並不確定:我們看到一張履歷表,即便隱去名字、不知道這個人是誰,也知道其中的各種信息是與某人關聯的。
在數字化的世界裡,不和其他的符號(數字)關聯的符號(數字)是不包含任何信息的。從不包含信息的素材,得不到包含信息的結論。
有人可能反對這個觀點:谷歌曾經用「感冒」的搜索量預報流感啊,這裡哪有關聯呢?其實,只有搜索「感冒」的數量是根本無法預測流感的。谷歌的做法,是把「感冒」的搜索與搜索的地點、時間聯繫起來。
這個觀點告訴我們:收集數據的時候,要儘可能地把關聯關係建立起來;沒有關聯關係,數據很容易成為垃圾。這種情況並不少見:有些實驗室,把針對同一試樣的各項實驗結果分別保存起來,而沒有建立統一的ID、關聯關係丟失。這樣的數據,再多也沒有用處。

2、人們要挖掘的知識和信息,就是找映射關係
知識(或信息)的發現與挖掘,其本質是尋找映射關係:通過已知的、對象的一部分屬性,把對象的另外一部分屬性或對象本身找出來(或縮小範圍)。產生這類問題的原因是:只有一部分屬性已知、容易得到、容易識別、容易表述,而另外一部分未知、不容易得到、不容易識別、不容易描述。
例如,我們可以說:張三就是那個穿紅衣服的——這裡「穿紅衣服」比其他特徵容易識別。從衣服識別出張三,就是從張三的衣著特徵(屬性)找到關聯對象(張三)的信息;從一個人的身高預估他的體重,就是從一個根據一類屬性估計另外一類屬性。
我習慣於把信息挖掘和知識發現分開。
在本文中,信息挖掘指的是預測某個特定對象的屬性,如上海市的人口是多少;知識發現是確定一類對象的屬性之間的關係,如一類人群中身高和體重的關係。當然,這種區分不是絕對的。
3、映射關係的差別
正確的識別,最好的辦法是找到好的素材(數據)。素材與結果之間的關聯強度是不一樣的:有的比較強,是因果關係、必然聯繫;有的比較弱,是相關關係、偶然聯繫。
例如,我們可以根據DNA、相貌、衣服來識別一個人。但三者相比,DNA的聯繫是強的必然性聯繫、衣服是弱的偶然性聯繫,相貌是介於兩者之間的聯繫。大數據的一個著名案例,是網站根據客戶買的葯判斷她已懷孕、並推送有關產品:因為這種葯只有孕婦才吃,是很強的關聯。
從數據得到的知識和信息,往往不是絕對正確。一般來說,可靠的結論基於可靠的數據和可靠的分析方法。數據量大了以後,濾除干擾的可能性增大,從而可以從原來可靠度低的數據中,得到可靠性相對較高的數據。
所以,盡量找到好的素材,是做好分析的第一步。
在很多情況下,我們找不到好的素材。這時,首先要做的盡量提高數據質量。數據質量不僅是精度問題,還包括數據來源的可靠性:為此,需要把數據來源的相關過程要搞清楚,否則很可能會誤導人的分析。
4、相關與因果
有些相關性的背後,一般會有因果關係存在。兩個要素由因果產生關聯的機制大概可以分成兩類:1、兩個要素具有因果的關係:比如剛做父親的青年人常會買尿布;2、共同原因導致的兩個結果之間的關係:比如孩子的父親會常買啤酒,也常買尿布;於是,啤酒和尿布就可能關聯起來。
有些相關性,看似沒有因果,但背後往往有某些特殊的規律或因素其作用(上述第二種情況)。比如,女孩子往往喜歡花衣服,與基因和文化的共性有關。但這種因果關係可能相隔太遠,以至於難以考證了。
當人們需要根據關係作出決策時,需要研究因果的邏輯關係:到底是誰影響了誰。否則,根據分析結構的盲目行為可能適得其反。 「到底誰影響了誰」為什麼會成為問題?大概有兩類原因:
第一類原因是:忽視了時間因素。如「統計結果表明,練太極拳的身體差」。現實卻是:很多人身體變差(包括衰老)以後,才練太極拳。一般來說,具有因果關係的兩個要素之間,時間上有前後關係:原因早前,結果在後。
第二類原因是:忽視了前導因素。「公雞一叫,天就亮了」。現實卻是,天量之前的跡象被公雞察覺到了。兩者是第二種因果關係,只是看似「原因在後、結果在前」了。
一般來說,工業大數據分析更重視因果,而商務大數據分析對因果性的要求較弱。
5、數據分析的先導因素
從某種意義上說,數據分析的過程,就是尋找強的相關關係(必然性、因果性),或對弱的相關關係進行綜合、得到強的相關關係。
用數據發現信息,需要用到各種知識。例如,把「雲南白藥是用於治療外傷的」放入計算機,當某人購買白葯的行為判斷他或家人可能受傷,從而可以推薦相關產品。但注意到:這種類型的知識很可能是被人事先裝入計算機的,而不是靠計算機自動學習得到的。
所有的學習過程,本質上都是基於這樣一種假設:A和B的一部分屬性類似,則推測另一部分屬性也應該類似。例如,A和B的身高相似,則體重也可能相似。現實中,兩個屬性確實具有強烈的相關性,但身高相同而體重不同的也大有人在。這時,如果我們還知道他的體型,是瘦弱、偏瘦、正常、偏胖、肥胖型,對體重的估計就可以準確一些。由此可見,用數據發現知識的過程,本質上就是提高相關性、可靠性的過程。
一般來說,人們在做數據分析之前,一定會有一定的知識積澱, 但認識不清卻是一種常態;人們希望通過對數據的分析,來改變這種常態。而改變認識的過程依賴於數據的質量和分析數據的方法。所以,刨除分析方法外,分析過程依賴於兩個先導性因素:1、數據質量(包含多方面的含義)如何;人們已有的認識如何。
注意,這段說法有個潛台詞:強調了人類可認識的知識,而不是機器用複雜函數關係表述的、人類難以用邏輯關係認知的知識(如神經元)。的確如此,筆者一直認為:這類方法的作用被學術界有意識地誇大了。
6、數據分析的過程
與商業智慧大數據相比,工業大數據更重視可靠性和精確性。在很多情況下,猜出一個結論並不難,難的是論證一個結論。一般來說,凡是可靠的知識,都應該能夠被機理和數據雙重認證。
大數據分析的一個重要特徵是:傳統概率理論的假設往往不成立。例如:大數定理的條件往往不成立、模型的結構往往未知、因果關係不是天然清晰、自變數的誤差往往不能忽略、數據分布往往是沒有規律的。所以,為了得到可靠的結果,人們工作的重點很可能是驗證這些條件、構造這些條件。從某種意義上說,數據分析的過程,主要是排除干擾的過程、特別是排除系統干擾的過程。而且,如果完全依照邏輯、用純粹數學的辦法加以論證,則數據需求量會遭遇「組合爆炸」,永遠是不夠的。這時,已有的領域知識就是降低數據需求量的一種手段。要記住:求得可靠性是一個過程而不是結果、可能永遠沒有終點;分析的過程只是不斷增加證據而已。這個過程,是修正人的認識的過程;所以,錯誤或不恰當的認識常常是分析過程中最大的干擾——這個干擾一旦去除,我們可能就發現了真正的知識。
數據量大的直接好處,是排除隨機性干擾。但排除系統性干擾卻不那麼容易,數據量大是必要條件但不充分,需要深入的方法研究才能解決問題。
系統性的干擾往往體現在:對主體進行分組,所體現的規律是不同的。比如,身高和體重的統計關係,男女是不同的、不同民族是有差異的、可能與年齡有關。如果不進行分類研究,統計的結果就會與樣本的選取有很大關係。但分類研究也會遇到一個困難:遭遇組合爆炸,數據再多都不夠用。這時,「領域知識」就會發生作用:
認定一個結論成立的辦法,是確認它的「可重複性」。在許多情況下,「可重複性」指的是在各種分組下都成立的結論:最好能在不同時間分組中也能成立。分組越多、分組的維度越多、結論的可靠性越高。
但具有「可重複性」的結論,往往只在一定的範圍內成立。在很多情況下,「明確結論成立的範圍」也是數據分析的重要內容。
如何分組、如何確定範圍、如何構築邏輯鏈條、數據結果的解讀、數據結果與領域知識的融合,都是重要的能力。事實上,根據領域知識,常常用於構造證據鏈、進行有效的數據選取和分組。
在精密論證時,我們就會發現:基礎數據的質量很重要。因為許多干擾就來源於數據本身。從某種意義上說,數據的採集方法和環境不同,就是不同的數據。
在構建數據分析體系的過程中,也會發現,企業經營的數據分析也確實需要一個可展示的平台,實時展示業務,有問題就優化更新。
FineReport 數據決策系統
7、關於預測數字
許多問題分析的目的得到一個數字:如鋼的強度、用電量、人口數量、鋼產量。這類問題的特點之一是:最終的結果是各種影響因素相加得到的。
對於這種問題,我的觀點是:要想得到可靠的結果,一定要拆成若干子問題來分析。其中,各個子問題要儘可能利用規律性的結果來分析。我認為:把人的認識和數據用到極致的時候,才能得到最好的結果。隨便地建立回歸模型是不懂數據的表現。
作者:郭朝暉
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!