下面的內容,是筆者在學習和工作中的一些總結,其中概念性的內容大多來自書中,實踐性的內容大多來自自己的工作和個人理解。由於資歷尚淺,難免會有很多錯誤,望批評指正!
概述
數據倉庫包含的內容很多,它可以包括架構、建模和方法論。對應到具體工作中的話,它可以包含下面的這些內容:
1、以Hadoop、Spark、Hive等組建為中心的數據架構體系。
2、各種數據建模方法,如維度建模。
3、調度系統、元數據系統、ETL系統、可視化系統這類輔助系統。
4、我們暫且不管數據倉庫的範圍到底有多大,在數據倉庫體系中,數據模型的核心地位是不可替代的。
因此,下面的將詳細地闡述數據建模中的典型代表:維度建模,對它的的相關理論以及實際使用做深入的分析。
文章結構
本文將按照下面的順序進行闡述:
先介紹比較經典和常用的數據倉庫模型,並分析其優缺點。
詳細介紹維度建模的基本概念以及相關理論。
為了能更真切地理解什麼是維度建模,我將模擬一個大家都十分熟悉的電商場景,運用前面講到的理論進行建模。
理論和現實的工作場景畢竟會有所差距,這一塊,我會分享一下企業在實際的應用中所做出的取捨。
0x01 經典數據倉庫模型
下面將分別介紹四種數據倉庫模型,其中前三種模型分別對應了三本書:《數據倉庫》、《數據倉庫工具箱》和《數據架構 大數據 數據倉庫以及Data Vault》,這三本書都有中文版,非常巧的是,我只有三本數據倉庫的書,正好對應了這三種理論。
Anchor模型我並不是特別熟悉,放在這裡以供參考。
一、實體關係(ER)模型
數據倉庫之父Immon的方法從全企業的高度設計一個3NF模型,用實體加關係描述的數據模型描述企業業務架構,在範式理論上符合3NF,它與OLTP系統中的3NF的區別,在於數據倉庫中的3NF上站在企業角度面向主題的抽象,而不是針對某個具體業務流程的實體對象關係抽象,它更多的是面向數據的整合和一致性治理,正如Immon所希望達到的:「single version of the truth」。
但是要採用此方法進行構建,也有其挑戰:
1、需要全面了解企業業務和數據
2、實施周期非常長
3、對建模人員的能力要求也非常高
二、維度模型
維度模型是數據倉庫領域另一位大師Ralph Kimall所倡導,他的《The DataWarehouse Toolkit-The Complete Guide to Dimensona Modeling,中文名《數據倉庫工具箱》,是數據倉庫工程領域最流行的數倉建模經典。維度建模以分析決策的需求出發構建模型,構建的數據模型為分析需求服務,因此它重點解決用戶如何更快速完成分析需求,同時還有較好的大規模複雜查詢的響應性能。
典型的代表是我們比較熟知的星形模型,以及在一些特殊場景下適用的雪花模型。
三、DataVault
DataVault是Dan Linstedt發起創建的一種模型方法論,它是在ER關係模型上的衍生,同時設計的出發點也是為了實現數據的整合,並非為數據決策分析直接使用。它強調建立一個可審計的基礎數據層,也就是強調數據的歷史性可追溯性和原子性,而不要求對數據進行過度的一致性處理和整合;同時也基於主題概念將企業數據進行結構化組織,並引入了更進一步的範式處理來優化模型應對源系統變更的擴展性。
它主要由:Hub(關鍵核心業務實體)、Link(關係)、Satellite(實體屬性) 三部分組成 。
四、Anchor模型
Anchor模型是由Lars. Rönnbäck設計的,初衷是設計一個高度可擴展的模型,核心思想:所有的擴展只是添加而不是修改,因此它將模型規範到6NF,基本變成了K-V結構模型。
Anchor模型由:Anchors 、Attributes 、Ties 、Knots 組成,相關細節可以參考《AnchorModeling-Agile Information Modeling in Evolving Data Environments》
0x02 維度建模
一、什麼是維度建模
維度模型是數據倉庫領域大師Ralph Kimall所倡導,他的《數據倉庫工具箱》,是數據倉庫工程領域最流行的數倉建模經典。維度建模以分析決策的需求出發構建模型,構建的數據模型為分析需求服務,因此它重點解決用戶如何更快速完成分析需求,同時還有較好的大規模複雜查詢的響應性能。
我們換一種方式來解釋什麼是維度建模。學過資料庫的童鞋應該都知道星型模型,星型模型就是我們一種典型的維度模型。我們在進行維度建模的時候會建一張事實表,這個事實表就是星型模型的中心,然後會有一堆維度表,這些維度表就是向外發散的星星。那麼什麼是事實表、什麼又是維度表嗎,下面會專門來解釋。
二、維度建模的基本要素
維度建模中有一些比較重要的概念,理解了這些概念,基本也就理解了什麼是維度建模。
1. 事實表
發生在現實世界中的操作型事件,其所產生的可度量數值,存儲在事實表中。從最低的粒度級別來看,事實錶行對應一個度量事件,反之亦然。
額,看了這一句,其實是不太容易理解到底什麼是事實表的。
比如一次購買行為我們就可以理解為是一個事實,下面我們上示例。
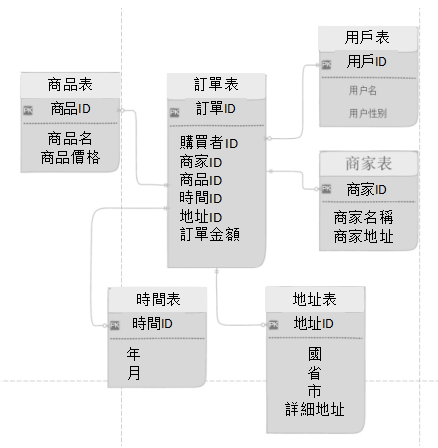
圖中的訂單表就是一個事實表,你可以理解他就是在現實中發生的一次操作型事件,我們每完成一個訂單,就會在訂單中增加一條記錄。
我們可以回過頭再看一下事實表的特徵,在維度表裡沒有存放實際的內容,他是一堆主鍵的集合,這些ID分別能對應到維度表中的一條記錄。
2. 維度表
每個維度表都包含單一的主鍵列。維度表的主鍵可以作為與之關聯的任何事實表的外鍵,當然,維度錶行的描述環境應與事實錶行完全對應。 維度表通常比較寬,是扁平型非規範表,包含大量的低粒度的文本屬性。
我們的圖中的用戶表、商家表、時間表這些都屬於維度表,這些表都有一個唯一的主鍵,然後在表中存放了詳細的數據信息。
0x03 實踐
下面我們將以電商為例,詳細講一下維度建模的建模方式,並舉例如果使用這個模型(這點還是很重要的)。
一、業務場景
假設我們在一家電商網站工作,比如某寶、某東。我們需要對這裡業務進行建模。下面我們分析幾點業務場景:
1、電商網站中最典型的場景就是用戶的購買行為。
2、一次購買行為的發起需要有這幾個個體的參與:購買者、商家、商品、購買時間、訂單金額。
3、一個用戶可以發起很多次購買的動作。
好,基於這幾點,我們來設計我們的模型。
二、模型設計
下面就是我們設計出來的數據模型,和之前的基本一樣,只不過是換成了英文,主要是為了後面寫sql的時候來用。
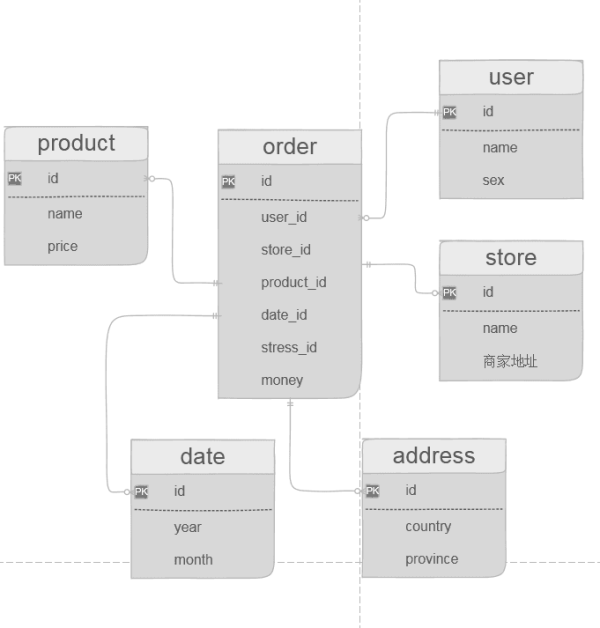
我就不再解釋每個表的作用了,現在只說一下為什麼要這樣設計。
首先,我們想一下,如果我們不這樣設計的話,我們一般會怎麼做?
如果是我,我會設計下面這張表。你信不信,我能列出來50個欄位!其實我個人認為怎麼設計這種表都有其合理性,我們不論對錯,單說一下兩者的優缺點。
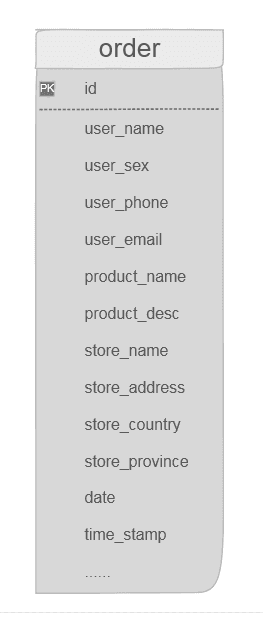
先說我們的維度模型:
1、數據冗餘小(因為很多具體的信息都存在相應的維度表中了,比如用戶信息就只有一份)
2、結構清晰(表結構一目了然)
3、便於做OLAP分析(數據分析用起來會很開心)
4、增加使用成本,比如查詢時要關聯多張表
5、數據不一致,比如用戶發起購買行為的時候的數據,和我們維度表裡面存放的數據不一致
再說我們這張大款表的優缺點:
1、業務直觀,在做業務的時候,這種報表製作特別方便,直接能對到業務中。
2、使用方便,寫sql的時候很方便。
3、數據冗餘巨大,真的很大,在幾億的用戶規模下,他的訂單行為會很恐怖
4、粒度僵硬,什麼都寫死了,這張表的可復用性太低。
三、使用示例
數據模型的建立必須要為更好的應用來服務,下面我先舉一個例子,來切實地感受一下來怎麼用我們的模型。
需求:求出2016年在帝都的男性用戶購買的LV品牌商品的總價格。
實現:
SELECT
SUM(order.money)
FROM
order,
product,
date,
address,
user,
WHERE
date.year = ‘2016’
AND user.sex = ‘male’
AND address.province = ‘帝都’
AND product.name = ‘LV’
0xFF 總結
維度建模是一種十分優秀的建模方式,他有很多的優點,但是我們在實際工作中也很難完全按照它的方式來實現,都會有所取捨,比如說為了業務我們還是會需要一些寬表,有時候還會有很多的數據冗餘。
作者:dantezhao |簡書 | CSDN | GITHUB
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!