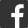最近出現了好幾次同樣的對話場景:
問:你是做什麼的?
答:最近在搞數據倉庫。
問:哦,你是傳統行業的吧,我是搞大數據的。
答:……
發個牢騷,搞大數據的也得建設數據倉庫吧。而且不管是傳統行業還是現在的互聯網公司,都需要對數據倉庫有一定的重視,而不是談一句自己是搞大數據的就很厲害了。數據倉庫更多代表的是一種對數據的管理和使用的方式,它是一整套包括了etl、調度、建模在內的完整的理論體系。現在所謂的大數據更多的是一種數據量級的增大和工具的上的更新。 兩者並無衝突,相反,而是一種更好的結合。
話說,單純用用Hadoop、Spark、Flume處理處理數據,其實只是學會幾種新的工具,這是搞工具的,只是在數據倉庫中etl中的一部分。
當然,技術的更新往往能領到一個時代的變革,比如Hadoop的誕生,光是深入研究一個大數據組件就要花很大的時間和精力。但是在熱潮冷卻之後,我們更應該考慮地是如何更好地管理和使用自己的數據。
對於數據的從業者來講,要始終重視緊跟技術的變革,但是切記數據為王,在追求技術的極致的時候,不要忘了我們是搞數據的。
文章主題
吐槽完畢,本文主要講解數據倉庫的一個重要環節:如何設計數據分層!,其它關於數據倉庫的內容可參考其它的文章數據倉庫。
本文對數據分層的討論適合下面一些場景,超過該範圍場景 or 數據倉庫經驗豐富的大神就不必浪費時間看了。
數據建設剛起步,大部分的數據經過粗暴的數據接入後就直接對接業務。
數據建設發展到一定階段,發現數據的使用雜亂無章,各種業務都是從原始數據直接計算而得。
各種重複計算,嚴重浪費了計算資源,需要優化性能。
文章結構
最初在做數據倉庫的時候遇到了很多坑,由於自身資源有限,接觸數據倉庫的時候,感覺在互聯網行業裡面的數據倉庫成功經驗很少,網上很難找到比較實踐性強的資料。而那幾本經典書籍裡面又過於理論,折騰起來真是生不如死。還好現在過去了那個坎,因此多花一些時間整理自己的思路,幫助其他的小夥伴少踩一些坑。
1、為什麼要分層?這個問題被好幾個同學質疑過。因此分層的價值還是要說清楚的。
2、分享一下經典的數據分層模型,以及每一層的數據的作用和如何加工得來。
3、分享兩個數據分層的設計,通過這兩個實際的例子來說明每一層該怎麼存數據。
4、給出一些建議,不是最好的,但是可以做參考。
0x01 為什麼要分層
我們對數據進行分層的一個主要原因就是希望在管理數據的時候,能對數據有一個更加清晰的掌控,詳細來講,主要有下面幾個原因:
1、清晰數據結構:每一個數據分層都有它的作用域,這樣我們在使用表的時候能更方便地定位和理解。
2、數據血緣追蹤:簡單來講可以這樣理解,我們最終給業務誠信的是一能直接使用的張業務表,但是它的來源有很多,如果有一張來源表出問題了,我們希望能夠快速準確地定位到問題,並清楚它的危害範圍。
3、減少重複開發:規範數據分層,開發一些通用的中間層數據,能夠減少極大的重複計算。
4、把複雜問題簡單化。講一個複雜的任務分解成多個步驟來完成,每一層只處理單一的步驟,比較簡單和容易理解。而且便於維護數據的準確性,當數據出現問題之後,可以不用修復所有的數據,只需要從有問題的步驟開始修復。
5、屏蔽原始數據的異常。
6、屏蔽業務的影響,不必改一次業務就需要重新接入數據。
數據體系中的各個表的依賴就像是電線的流向一樣,我們都希望它是很規整,便於管理的。但是,最終的結果大多是第一幅圖,而非第二幅圖。


0x02 怎樣分層
理論
我們從理論上來做一個抽象,可以把數據倉庫分為下面三個層,即:數據運營層、數據倉庫層和數據產品層。
1. ODS全稱是Operational Data Store,操作數據存儲
「面向主題的」,數據運營層,也叫ODS層,是最接近數據源中數據的一層,數據源中的數據,經過抽取、洗凈、傳輸,也就說傳說中的ETL之後,裝入本層。本層的數據,總體上大多是按照源頭業務系統的分類方式而分類的。
例如這一層可能包含的數據表為:人口表(包含每個人的身份證號、姓名、住址等)、機場登機記錄(包含乘機人身份證號、航班號、乘機日期、起飛城市等)、銀聯的刷卡信息表(包含銀行卡號、刷卡地點、刷卡時間、刷卡金額等)、銀行賬戶表(包含銀行卡號、持卡人身份證號等)等等一系列原始的業務數據。這裡我們可以看到,這一層面的數據還具有鮮明的業務資料庫的特徵,甚至還具有一定的關係資料庫中的數據範式的組織形式。
但是,這一層面的數據卻不等同於原始數據。在源數據裝入這一層時,要進行諸如去噪(例如去掉明顯偏離正常水平的銀行刷卡信息)、去重(例如銀行賬戶信息、公安局人口信息中均含有人的姓名,但是只保留一份即可)、提臟(例如有的人的銀行卡被盜刷,在十分鐘內同時有兩筆分別在中國和日本的刷卡信息,這便是臟數據)、業務提取、單位統一、砍欄位(例如用於支撐前端系統工作,但是在數據挖掘中不需要的欄位)、業務判別等多項工作。
2. 數據倉庫層(DW),是數據倉庫的主體
在這裡,從ODS層中獲得的數據按照主題建立各種數據模型。例如以研究人的旅遊消費為主題的數據集中,便可以結合航空公司的登機出行信息,以及銀聯繫統的刷卡記錄,進行結合分析,產生數據集。在這裡,我們需要了解四個概念:維(dimension)、事實(Fact)、指標(Index)和粒度( Granularity)。
3. 數據產品層(APP),這一層是提供為數據產品使用的結果數據
在這裡,主要是提供給數據產品和數據分析使用的數據,一般會存放在es、mysql等系統中供線上系統使用,也可能會存在Hive或者Druid中供數據分析和數據挖掘使用。
比如我們經常說的報表製作數據,或者說那種大寬表,一般就放在這裡。
技術實踐
這三層技術劃分,相對來說比較粗粒度,後面我們會專門細分一下。在此之前,先聊一下每一層的數據一般都是怎麼流向的。這裡僅僅簡單介紹幾個常用的工具,側重中開源界主流。
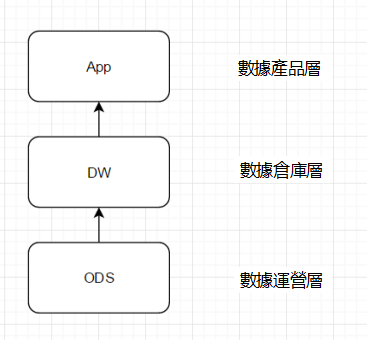
1. 數據來源層–> ODS層
這裡其實就是我們現在大數據分析軟體技術發揮作用的一個主要戰場。 我們的數據主要會有兩個大的來源:
1、業務庫,這裡經常會使用sqoop來抽取,比如我們每天定時抽取一次。在實時方面,可以考慮用canal監聽mysql的binlog,實時接入即可。
埋點日誌,線上系統會打入各種日誌,這些日誌一般以文件的形式保存,我們可以選擇用flume定時抽取,也可以用用spark streaming或者2、storm來實時接入,當然,kafka也會是一個關鍵的角色。
3、其它數據源會比較多樣性,這和具體的業務相關,不再贅述。
注意: 在這層,理應不是簡單的數據接入,而是要考慮一定的數據清洗,比如異常欄位的處理、欄位命名規範化、時間欄位的統一等,一般這些很容易會被忽略,但是卻至關重要。特別是後期我們做各種特徵自動生成的時候,會十分有用。後續會有文章來分享。
2. ODS、DW –> App層
這裡面也主要分兩種類型:
每日定時任務型:比如我們典型的日計算任務,每天凌晨算前一天的數據,早上起來看報表。 這種任務經常使用Hive、Spark或者生擼MR程序來計算,最終結果寫入Hive、Hbase、Mysql、Es或者Redis中。
實時數據:這部分主要是各種實時的系統使用,比如我們的實時推薦、實時用戶畫像,一般我們會用Spark Streaming、Storm或者Flink來計算,最後會落入Es、Hbase或者Redis中。
0x03 舉個例子
網上的例子很多,就不列了,只舉個筆者早期參與設計的數據分層例子。分析一下當初的想法,以及這種設計的缺陷。上原圖(此處@Ruby大神。現實是我只是個打醬油的。盜圖、盜思想。)
當初的設計總共分了6層,其中去掉元數據後,還有5層。下面分析一下當初的一個設計思路。
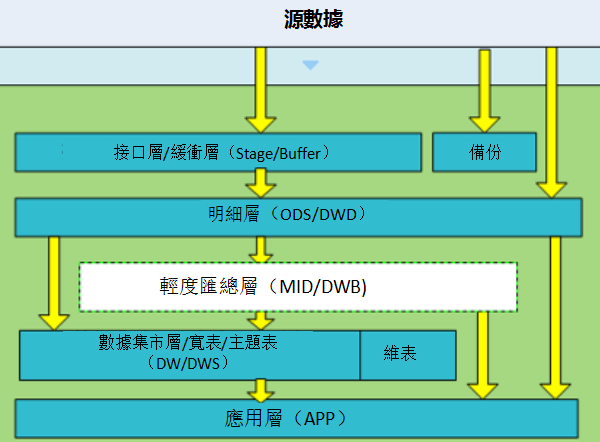
緩衝層(buffer)
概念:又稱為介面層(stage),用於存儲每天的增量數據和變更數據,如Canal接收的業務變更日誌。
數據生成方式:直接從kafka接收源數據,需要業務表每天生成update,delete,inseret數據,只生成insert數據的業務表,數據直接入明細層
討論方案:只把canal日誌直接入緩衝層,如果其它有拉鏈數據的業務,也入緩衝層。
日誌存儲方式:使用impala外表,parquet文件格式,方便需要MR處理的數據讀取。
日誌刪除方式:長久存儲,可只存儲最近幾天的數據。討論方案:直接長久存儲
表schema:一般按天創建分區
庫與表命名。庫名:buffer,表名:初步考慮格式為:buffer_日期_業務表名,待定。
明細層(ODS, Operational Data Store,DWD: data warehouse detail)
概念:是數據倉庫的細節數據層,是對STAGE層數據進行沉澱,減少了抽取的複雜性,同時ODS/DWD的信息模型組織主要遵循企業業務事務處理的形式,將各個專業數據進行集中,明細層跟stage層的粒度一致,屬於分析的公共資源
數據生成方式:部分數據直接來自kafka,部分數據為介面層數據與歷史數據合成。
canal日誌合成數據的方式待研究。
討論方案:canal數據的合成方式為:每天把明細層的前天全量數據和昨天新數據合成一個新的數據表,覆蓋舊錶。同時使用歷史鏡像,按周/按月/按年 存儲一個歷史鏡像到新表。
日誌存儲方式:直接數據使用impala外表,parquet文件格式,canal合成數據為二次生成數據,建議使用內表,下面幾層都是從impala生成的數據,建議都用內表+靜態/動態分區。
日誌刪除方式:長久存儲。
表schema:一般按天創建分區,沒有時間概念的按具體業務選擇分區欄位。
庫與表命名。庫名:ods,表名:初步考慮格式為ods_日期_業務表名,待定。
舊數據更新方式:直接覆蓋
輕度匯總層(MID或DWB, data warehouse basis)
概念:輕度匯總層數據倉庫中DWD層和DM層之間的一個過渡層次,是對DWD層的生產數據進行輕度綜合和匯總統計(可以把複雜的清洗,處理包含,如根據PV日誌生成的會話數據)。輕度綜合層與DWD的主要區別在於二者的應用領域不同,DWD的數據來源於生產型系統,並未滿意一些不可預見的需求而進行沉澱;輕度綜合層則面向分析型應用進行細粒度的統計和沉澱
數據生成方式:由明細層按照一定的業務需求生成輕度匯總表。明細層需要複雜清洗的數據和需要MR處理的數據也經過處理後接入到輕度匯總層。
日誌存儲方式:內表,parquet文件格式。
日誌刪除方式:長久存儲。
表schema:一般按天創建分區,沒有時間概念的按具體業務選擇分區欄位。
庫與表命名。庫名:dwb,表名:初步考慮格式為:dwb_日期_業務表名,待定。
舊數據更新方式:直接覆蓋
主題層(DM,date market或DWS, data warehouse service)
概念:又稱數據集市或寬表。按照業務劃分,如流量、訂單、用戶等,生成欄位比較多的寬表,用於提供後續的業務查詢,OLAP分析,數據分發等。
數據生成方式:由輕度匯總層和明細層數據計算生成。
日誌存儲方式:使用impala內表,parquet文件格式。
日誌刪除方式:長久存儲。
表schema:一般按天創建分區,沒有時間概念的按具體業務選擇分區欄位。
庫與表命名。庫名:dm,表名:初步考慮格式為:dm_日期_業務表名,待定。
舊數據更新方式:直接覆蓋
應用層(App)
概念:應用層是根據業務需要,由前面三層數據統計而出的結果,可以直接提供查詢展現,或導入至Mysql中使用。
數據生成方式:由明細層、輕度匯總層,數據集市層生成,一般要求數據主要來源於集市層。
日誌存儲方式:使用impala內表,parquet文件格式。
日誌刪除方式:長久存儲。
表schema:一般按天創建分區,沒有時間概念的按具體業務選擇分區欄位。
庫與表命名。庫名:暫定apl,另外根據業務不同,不限定一定要一個庫。
舊數據更新方式:直接覆蓋
0x04 如何更優雅一些
前面提到的一種設計其實相對來講已經很詳細了,但是可能層次會有一點點多,而且在區分一張表到底該存放在什麼位置的時候可能還有一點點疑惑。 我們在這一章里再設計一套數據倉庫的分層,同時在前面的基礎上加上維表和一些臨時圖表製作的考慮,來讓我們的方案更優雅一些。
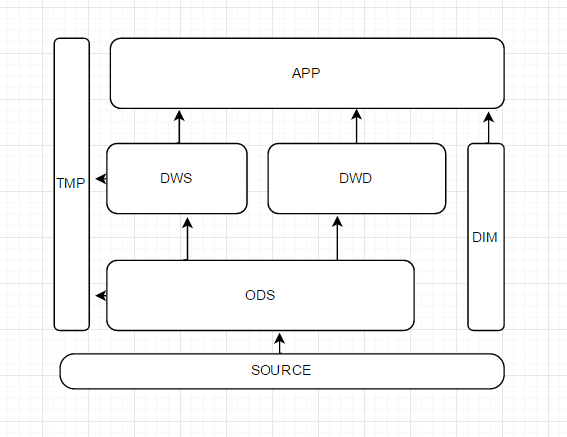
下圖,做了一些小的改動,我們去掉了上一節的Buffer層,把數據集市層和輕度匯總層放在同一個層級上,同時獨立出來了維表和臨時表。
這裡解釋一下DWS、DWD、DIM和TMP的作用。
DWS:輕度匯總層,從ODS層中對用戶的行為做一個初步的匯總,抽象出來一些通用的維度:時間、ip、id,並根據這些維度做一些統計值,比如用戶每個時間段在不同登錄ip購買的商品數等。這裡做一層輕度的匯總會讓計算更加的高效,在此基礎上如果計算僅7天、30天、90天的行為的話會快很多。我們希望80%的業務都能通過我們的DWS層計算,而不是ODS。
DWD:這一層主要解決一些數據質量問題和數據的完整度問題。比如用戶的資料信息來自於很多不同表,而且經常出現延遲丟數據等問題,為了方便各個使用方更好的使用數據,我們可以在這一層做一個屏蔽。
DIM:這一層比較單純,舉個例子就明白,比如國家代碼和國家名、地理位置、中文名、國旗圖片等信息就存在DIM層中。
TMP:每一層的計算都會有很多臨時表,專設一個DWTMP層來存儲我們數據倉庫的臨時表。
0x05 問答
有讀者問了一些問題,是我之前有一些沒講清楚,補到這裡。
問:dws和dwd是並行而不是先後順序?
答:並行的,dw層
問:那其實對於同一個數據,這兩個過程是串列的?
答:dws 會做匯總,dwd和ods的粒度相同,這兩層之間也沒有依賴的關係
問:對呀,那這樣dws裡面的匯總沒有經過數據質量和完整度的處理,或者單獨做了這種質量相關的處理,為什麼不在dwd之上再做匯總呢?我的疑問其實就是,dws的輕度匯總數據結果,有沒有做數據質量的處理?
答:ods 之間到dws就好 沒必要過dwd,我舉個例子,你的瀏覽商品行為,我做一層輕度匯總,就直接放在dws了。但是你的資料表,要從好多表湊成一份,我們從四五分個人資料表中 湊出來了一份完整的資料表放在了dwd中。然後在app層,我們要出一張畫像表,包含用戶資料和用戶近一年的行為,我們就直接從dwd中拿資料, 然後再在dws的基礎上做一層統計,就成一個app表了。
問:嗯,最後一個疑問,在現實生產中,可不可能存在計算dws時,會用到dwd表的情況?
答:不 這樣依賴就混了,dws不會依賴dwd,dws直接輕度匯總,業務用的話都說app。
問:就是說,dwd針對的是對象,它的數據質量處理有點像對用戶等等的實體信息的糾錯和匯總;dws針對的是行為,可以在某些維度上上卷的行為~
答:你這樣理解吧 dws存事實表,dwd 維度表。
0xFF 總結
數據分層是數據倉庫非常重要的一個環節,它決定的不僅僅是一個層次的問題,還直接影響到後續的血緣分析、特徵自動生成、元數據管理等一系列的建設。因此適於盡早考慮。
另外,每一層的名字不必太過在意,自己按照喜好就好。
本文分享了筆者自己對數據倉庫的一些理解和想法,不一定十分準確,有什麼問題可以多交流。
參考
《數據倉庫》
《數據倉庫工具箱》
Winston、Ruby的指導
作者:dantezhao |簡書 | CSDN | GITHUB
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!